

A Layman’s Guide to Dead Letter Queues (DLQ) with Google Pub/Sub
A guide to designing, and operating DLQs in production grade Pub/Sub systems

Dear readers,
A few years back, I was working on a system that sent welcome emails to new users during sign-up. The design was simple: a user performed an action, an event was published to a queue, a consumer picked it up and called the SendGrid API to deliver the email.
One day, we hit an unexpected snag. Our consumer was calling the SendGrid API just fine, but due to a small bug, it never marked the event as processed (acknowledged). The queue assumed the event wasn’t handled, so after the ack deadline expired, it redelivered the same event. The consumer retried the call, SendGrid happily sent the email again, and this loop kept repeating.
To make matters worse, we only had a single consumer instance. That one stuck event essentially blocked the entire queue. What looked like a harmless bug turned into dozens of duplicate emails and a completely clogged pipeline.
This kind of issue is known as the “poison pill” problem: one bad or unacknowledged message keeps coming back, poisoning the queue, and preventing healthy messages from being processed.
From Poison Pills to Dead Letter Queues
In this post, we’ll see how to stop a “poison pill” from poisoning our system. But before diving into the technical details, let’s imagine a simple real-world queue.
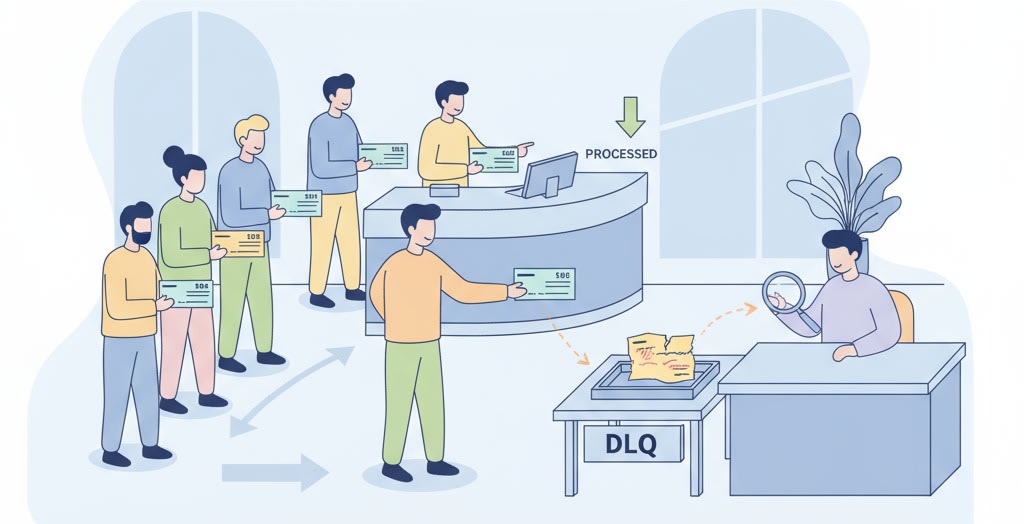
Imagine you’re at a bank where people line up to deposit checks. Each person hands their check to the cashier, who processes it one by one.
Now, if someone hands in a torn or illegible check, the cashier can’t process it. If they just keep holding on to that bad check, the entire line behind them comes to a halt.
A smarter system would be: put that bad check aside in a separate tray, let the rest of the line move forward, and later have a manager review the bad check to see what went wrong.
That’s exactly what a Dead Letter Queue (DLQ) does:
If a message in the queue can’t be processed (like the invalid check), it gets moved aside into a special holding area (the DLQ).
The rest of the messages keep flowing smoothly.
Later, engineers can look at the failed messages in the DLQ, fix them, and reprocess them if needed.
Designing the Dead Letter Queue
Now that we know what a Dead Letter Queue (DLQ) is, the real question is: how do we actually implement one?
Before jumping into code, it’s important to step back and design the mechanics carefully. A DLQ isn’t just a “dumping ground” for failed messages — it’s a deliberate safety net that requires us to make a few key decisions:
Identify failure modes
What kinds of errors can occur in your system?
Are they transient (like a temporary network blip or API timeout) or permanent (like malformed data or a missing required field)?
Define failure handling strategy
Which types of errors should trigger a retry?
Which should immediately route the message to the DLQ?
Set retry policies
How many times should a message be retried before we officially “give up”?
Should retries follow exponential backoff, fixed intervals, or custom logic?
Decide on metadata for DLQ messages
What extra information should we attach when moving a message to the DLQ? (e.g., error type, stack trace, retry count, correlation ID).
This metadata is crucial for debugging and reprocessing later.
Establish a “poison message” threshold
At what point do we stop retrying and mark a message as poisonous?
Once it’s in the DLQ, we don’t want it re-entering the main processing loop automatically and causing the same failure cycle.
Key Failure Modes and DLQ Strategies
Once we’ve defined what a DLQ should capture, the next step is to map out the different failure modes that can occur in a Pub/Sub-based system. Each type of failure needs its own handling strategy so that messages don’t get stuck in endless loops.
1. Consumer Failure Modes
When a Pub/Sub consumer cannot process a message:
Ack deadline: If the consumer doesn’t acknowledge within the ack deadline (default 10s, extendable to 600s), Pub/Sub assumes failure and redelivers the message.
Retries: Pub/Sub keeps retrying until the message is acknowledged or until it reaches the maximum delivery attempts (if a DLQ is configured).
Poison messages: Without a DLQ, one bad message can cycle forever, blocking or delaying other messages.
Strategies
Use idempotent consumers to make retries safe and avoid duplicate side effects (e.g., sending duplicate emails).
Implement ack deadline extensions for long-running jobs.
Configure a DLQ with max delivery attempts to prevent poison loops.
2. API Call Failures Inside Consumer
A common failure scenario is when your consumer depends on an external API (e.g., SendGrid, payment gateway) and that API either times out or returns a 5xx error.
Best practices
Use exponential backoff with jitter to retry API calls locally before giving up.
Apply circuit breakers to stop hammering unstable dependencies.
Ensure all external calls use idempotency keys so retries don’t cause duplicates.
If retries exceed the configured limit, route the message to DLQ.
3. Non-Recoverable Application Errors (e.g., NPE)
Not all failures are retryable. Some represent logic or data issues that will never succeed no matter how many times you retry:
Schema mismatch (e.g., invalid JSON).
Missing required fields in the payload.
Null pointer exceptions or bugs in business logic.
In such cases:
A DLQ helps capture the bad payload for later analysis.
But fixing the code (or correcting the data source) is mandatory before replaying.
Use a DB error log table to persist stack traces, consumer version, and raw payloads for debugging.
4. Pub/Sub DLQ vs. Error Log Table in a Database
When deciding how to capture failed messages, teams usually debate between using:
Pub/Sub Dead Letter Queues (DLQs)
A database-backed error log table
Both approaches have strengths and trade-offs.
Pub/Sub DLQ (Dead Letter Queue)
Pros
Automatically supported by Pub/Sub — easy to configure.
Handles high-throughput failures without manual scaling.
Allows attaching message attributes as metadata.
Messages can be re-subscribed to and reprocessed later.
Cons
Limited querying/filtering — replaying or analyzing requires additional tooling.
Costs grow with message volume and retention.
Error Log Table (e.g., Cloud SQL / PostgreSQL)
Pros
Full control: you can store payload + metadata + stack trace + retry count + consumer version.
Easy to query/filter (e.g., “show me all errors for consumer v2.1 in the last 24h”).
Can enrich with business metadata (user ID, category, severity).
Cons
Requires schema design, storage management, and indexing.
Not built for massive throughput unless carefully optimized.
Reprocessing requires custom scripts/tools.
Rule of thumb: Use Pub/Sub DLQ for operational resilience and quick retries, and use an error log DB for observability and analytics.
5. Republishing / Re-consuming Events
A DLQ is only useful if you can reprocess messages safely. Here’s how it works in both approaches:
From Pub/Sub Dead Letter Topic
Messages sit in a separate subscription.
Use
gcloud pubsub subscriptions pullor a custom consumer to fetch them.After analysis/fix, republish back to the main topic.
Use idempotency keys to avoid re-triggering duplicates.
From Error Log Table
Query failed rows (e.g., based on error category or timestamp).
Batch re-publish messages via a script or tool.
Ensure the re-publish process:
Updates a
reprocessed_attimestamp.Prevents double-sending if the same row is picked up again.
6. Hybrid Approach
In practice, many production systems use a hybrid strategy:
Pub/Sub DLQ handles high-throughput retries and keeps the main pipeline healthy.
Error Log Table provides deep visibility into why failures occurred, enriched with stack traces, error categories, and metadata for debugging.
Recommended flow:
Explaining the System Flow
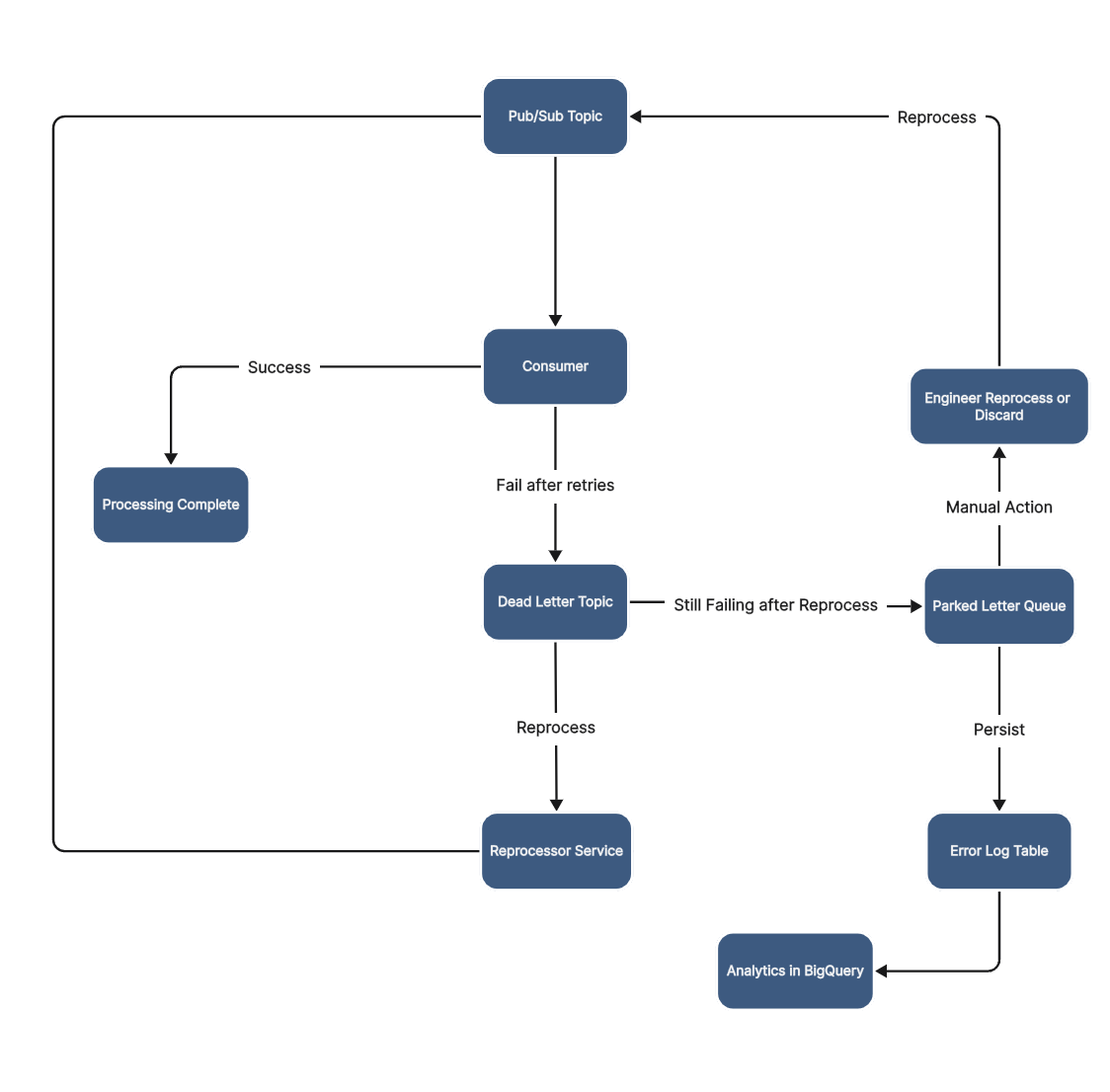
This flowchart represents the end-to-end lifecycle of a message in a Google Pub/Sub–based system with Dead Letter Queues (DLQs) and a Parked Letter Queue (PLQ) or the error table.
Let’s walk through each step:
1. Message Entry – Pub/Sub Topic
Everything begins with the Pub/Sub Topic.
Producers publish events here (e.g., “user signup,” “order created”).
Messages are then delivered to one or more Consumers for processing.
2. Consumer Processing
The Consumer is the application logic that processes each message.
Example: validating the payload, calling an external API, saving to DB, etc.
Two outcomes are possible:
Success: Message is acknowledged and marked as Processing Complete.
Failure after retries: Message is handed off to the Dead Letter Topic (DLQ).
3. Dead Letter Topic (DLQ) – Handling Transient Errors
The DLQ captures messages that couldn’t be processed even after retries.
These are typically transient issues, such as:
External API outages
Temporary DB lock
Network timeouts
To avoid losing data, we don’t discard these messages immediately. Instead:
A Reprocessor Service picks them up later and republishes them to the main topic for another attempt.
If successful, they continue as normal through the pipeline.
4. Parked Letter Queue (PLQ) – Handling Persistent Failures
If a DLQ message still fails even after reprocessing, it moves to the Parked Letter Queue (PLQ) or in this case, an error table.
The PLQ is the “quarantine area” for persistent or poison messages that won’t succeed automatically.
We can enhance the DLQ reprocessor to attach a custom attribute indicating how many times a message has landed in the DLQ. This way, the consumer application can use that metadata to decide when to route the message to the error log table.
Example causes:
Schema mismatch (e.g., missing required field)
Invalid payload (malformed JSON, bad encoding)
Application bug (NullPointerException)
5. Persistence and Analytics
Every message that enters the PLQ is persisted in an Error Log Table.
This table contains:
Raw payload
Error category
Stack trace or exception details
Retry count and consumer version
From here, the data flows into BigQuery for analytics and dashboards.
Teams can analyze trends (e.g., “What % of errors are API failures vs. schema mismatches?”).
Helps prioritize fixes and monitor long-term stability.
6. Manual Intervention
Engineers can manually inspect PLQ messages.
Based on investigation, they have two options:
Reprocess: Publish back into the Pub/Sub Topic once the root cause is fixed.
Discard: If the message is invalid and cannot be salvaged.
This ensures no data is lost silently and every failure path has a resolution.
Implementation: Building a True DLQ Pattern with Google Pub/Sub
Overview
This basic implementation would demonstrate a true Dead Letter Queue pattern using Google Pub/Sub, where:
ALL failures go to DLQ first (not directly to PLQ)
DLQ Reprocessor adds retry count metadata
Main Consumer makes PLQ decisions based on retry count
Manual intervention available via web dashboard
Key Principle
Message → Consumer → Fail → DLQ → Reprocessor → Add Retry Count → Main Topic → Consumer → Check Retry Count → If ≥3 → PLQ (Database)Prefer to skip the explanation and go straight to the implementation? The code is available here.
1. Producer Service
Location: producer-service/app.py
The producer publishes messages to the main topic:
@app.route('/publish', methods=['POST'])
def publish_message():
"""Publish a single message to the main topic"""
try:
data = request.get_json()
# Add metadata
message_data = {
**data,
"timestamp": datetime.now().isoformat(),
"producer_version": "1.0"
}
# Publish to main topic
message_id = pubsub_manager.publish_message(MAIN_TOPIC, message_data)
return jsonify({
"message_id": message_id,
"status": "published",
"timestamp": datetime.now().isoformat(),
"topic": MAIN_TOPIC
})Key Features:
REST API for message publishing
Automatic timestamp metadata
Sample message generation for testing
2. Consumer Service (Core DLQ Logic)
Location: consumer-service/app.py
This is the heart of the DLQ pattern implementation:
def process_message(self, message_data: Dict[Any, Any], message_id: str,
correlation_id: str = None, dlq_retry_count: int = 0) -> bool:
"""Process message with DLQ retry count awareness"""
try:
logger.info(f"Processing message {message_id}, type: {message_data.get('type')}, "
f"dlq_retry_count: {dlq_retry_count}")
# KEY LOGIC: Check if message exceeded DLQ retry limit
if dlq_retry_count >= 3: # Max DLQ retries
logger.info(f"Message {message_id} exceeded DLQ retry limit, sending to PLQ")
self._log_to_plq(
message_data, message_id, 'dlq_max_retries_exceeded',
f'Message failed after {dlq_retry_count} DLQ retries',
correlation_id=correlation_id, dlq_retry_count=dlq_retry_count
)
return True # Acknowledge the message (handled via PLQ)
# Check for simulated failures
failure_type = simulate_failure(message_data)
if failure_type:
logger.warning(f"Processing failed ({failure_type}), will go to DLQ")
# ALL failures go to DLQ (not directly to PLQ)
return False
# Normal processing...
return True
except Exception as e:
# Handle unexpected errors
if dlq_retry_count >= 3:
self._log_to_plq(message_data, message_id, error_type, error_message)
return True
return False # Let it go to DLQ for retry
Message Callback extracts retry count from attributes:
def callback(self, message):
"""Handle incoming Pub/Sub message"""
try:
message_data = json.loads(message.data.decode('utf-8'))
message_id = message.message_id
correlation_id = message.attributes.get('correlation_id')
# Extract DLQ retry count from message attributes
dlq_retry_count = int(message.attributes.get('dlq_retry_count', 0))
# Process with retry count awareness
success = self.process_message(
message_data, message_id, correlation_id, dlq_retry_count
)
if success:
message.ack() # Successfully processed
logger.info(f"Message processed successfully: {message_id}")
else:
message.nack() # Send to DLQ
logger.warning(f"Message nacked, will go to DLQ: {message_id}")
3. DLQ Reprocessor (Retry Count Manager)
Location: dlq-reprocessor/app.py
The reprocessor adds retry count metadata and republishes:
def reprocess_message(self, message_data: Dict[Any, Any], message_id: str,
correlation_id: str = None, dlq_retry_count: int = 0) -> bool:
"""Reprocess a message from DLQ with retry count tracking"""
try:
logger.info(f"Reprocessing message {message_id} (DLQ retry: {dlq_retry_count})")
# Check if should reprocess
should_reprocess, reason = self.should_reprocess(message_data, dlq_retry_count)
if not should_reprocess:
logger.info(f"Message not eligible: {reason}")
return True
# Enrich message with metadata
enriched_message = self.enrich_message_for_reprocess(message_data, dlq_retry_count)
# Apply exponential backoff delay
delay = self.reprocess_delay * (2 ** dlq_retry_count)
time.sleep(min(delay, 60)) # Cap at 60 seconds
# KEY: Add DLQ retry count to message attributes
attributes = {
'correlation_id': correlation_id or f"dlq_reprocess_{message_id}",
'dlq_retry_count': str(dlq_retry_count + 1), # Increment retry count!
'reprocess_timestamp': datetime.now().isoformat(),
'from_dlq': 'true'
}
# Republish to main topic with retry count
new_message_id = self.pubsub_manager.publish_message(
self.main_topic,
enriched_message,
attributes # This adds the retry count header!
)
logger.info(f"Message {message_id} republished as {new_message_id} "
f"with dlq_retry_count={dlq_retry_count + 1}")
return True
4. Error Storage (PLQ Implementation)
Location: support/database.py
Failed messages are stored in PostgreSQL for manual intervention:
def log_error(self, message_id: str, message_data: dict, error_type: str,
error_message: str, stack_trace: str = None,
correlation_id: str = None, dlq_retry_count: int = 0):
"""Log error to PLQ database"""
try:
query = """
INSERT INTO error_log
(message_id, message_data, error_type, error_message, stack_trace,
correlation_id, dlq_retry_count, created_at)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
with self.get_connection() as conn:
with conn.cursor() as cursor:
cursor.execute(query, (
message_id,
json.dumps(message_data),
error_type,
error_message,
stack_trace,
correlation_id,
dlq_retry_count, # Track retry count in database
datetime.now()
))
conn.commit()
5. Failure Simulation
Location: support/common.py
Realistic failure scenarios for testing:
def simulate_failure(message_data: Dict[Any, Any]) -> Optional[str]:
"""Simulate various failure scenarios for DLQ testing"""
# Check for explicit failure simulation
fail_simulation = message_data.get('fail_simulation')
if fail_simulation:
return fail_simulation
# Simulate random failures based on message content
email = message_data.get('email', '')
if email and not '@' in email:
return 'validation_error'
message_type = message_data.get('type')
if message_type == 'malformed_message':
return 'schema_error'
# Random API timeout (10% chance)
if random.random() < 0.1:
return 'api_timeout'
return None # No failure
Testing Guide
Step 1: Start the System
# Start all services
./start-system.sh
# Verify services are running
docker-compose ps
Expected Output:
NAME STATUS PORTS
dlq-test-consumer-service-1 Up X minutes
dlq-test-dlq-reprocessor-1 Up X minutes
dlq-test-postgres-1 Up X minutes (healthy) 0.0.0.0:5432->5432/tcp
dlq-test-producer-service-1 Up X minutes 0.0.0.0:8080->8080/tcp
dlq-test-pubsub-emulator-1 Up X minutes (healthy) 0.0.0.0:8085->8085/tcp
dlq-test-web-dashboard-1 Up X minutes 0.0.0.0:3000->3000/tcp
Step 2: Test Message Publishing
Test 1: Valid Message (Should Succeed)
curl -X POST http://localhost:8080/publish \
-H 'Content-Type: application/json' \
-d '{
"type": "user_signup",
"email": "test@example.com",
"name": "Test User"
}'
Expected Response:
{
"message_id": "1",
"status": "published",
"timestamp": "2025-09-11T18:42:31.069694",
"topic": "user-events"
}
Test 2: Invalid Message (Should Fail → DLQ)
curl -X POST http://localhost:8080/publish \
-H 'Content-Type: application/json' \
-d '{
"type": "user_signup",
"email": "invalid-email",
"name": "Invalid User",
"fail_simulation": "validation_error"
}'Test 3: Batch Test Messages
curl -X POST http://localhost:8080/publish/samplesExpected Response:
{
"description": "Published sample messages including some that will fail for DLQ testing",
"messages": [
{"message_id": "3", "type": "user_signup", "will_fail": false},
{"message_id": "4", "type": "user_signup", "will_fail": true},
{"message_id": "5", "type": "user_signup", "will_fail": true}
],
"published_count": 5
}
Step 3: Monitor DLQ Flow
Check Consumer Logs
docker-compose logs -f consumer-serviceExpected Output:
consumer-service-1 | INFO - Processing message 1, type: user_signup, dlq_retry_count: 0
consumer-service-1 | WARNING - Processing failed (validation_error), will go to DLQ, message_id: 2
consumer-service-1 | WARNING - Message nacked, will go to DLQ: 2Check DLQ Reprocessor Logs
docker-compose logs -f dlq-reprocessorExpected Output:
dlq-reprocessor-1 | INFO - Reprocessing message 2 (DLQ retry: 0)
dlq-reprocessor-1 | INFO - Message 2 republished as 8 with dlq_retry_count=1Check Consumer Processing Retry
docker-compose logs -f consumer-service | grep "dlq_retry_count"Expected Output:
consumer-service-1 | INFO - Processing message 8, type: user_signup, dlq_retry_count: 1
consumer-service-1 | INFO - Processing message 9, type: user_signup, dlq_retry_count: 2
consumer-service-1 | INFO - Message exceeded DLQ retry limit, sending to PLQStep 4: Verify PLQ Storage
docker-compose exec postgres psql -U dlq_user -d dlq_system-- Check error logs
SELECT id, message_id, error_type, dlq_retry_count, created_at
FROM error_log
ORDER BY created_at DESC
LIMIT 10;
-- Check PLQ messages (retry count >= 3)
SELECT message_id, error_type, dlq_retry_count
FROM error_log
WHERE dlq_retry_count >= 3;Step 5: Web Dashboard Testing
Open Dashboard: http://localhost:3000
View Error Statistics: Check failed message counts
Analytics Page: http://localhost:3000/analytics
Manual Intervention: Click on failed messages for details
Step 6: Comprehensive Test Script
# Run all test scenarios
./test-dlq-scenarios.shAccess the code here: Github
Summary
The poison pill problem shows how a single unprocessed message can bring down an entire pipeline. Dead Letter Queues (DLQs) provide a safety net by isolating failed messages so the rest of the system continues running smoothly.
In this post, we covered:
What DLQs are and how they solve the poison pill problem.
Design decisions around retries, failure modes, metadata, and thresholds.
Strategies for handling transient vs. permanent failures.
Trade-offs between Pub/Sub DLQs and database error tables.
Hybrid approach for combining operational resilience with deep visibility.
Implementation details with a true DLQ pattern in Google Pub/Sub, complete with reprocessing, retry counts, and error logging.
By designing DLQs carefully, you ensure that your system is:
Resilient: no single message can clog the pipeline.
Visible: errors are captured and analyzed.
Flexible: transient errors can be retried, permanent ones quarantined.
Controllable: engineers always have the final say through manual intervention.
Dead Letter Queues aren’t just about “dumping” bad messages, they’re about building robust, fault-tolerant pipelines that can gracefully handle the unexpected.
Great Explanation !