

How AWS Made 10 GB Lambda Container Images Feel Like 250 MB ZIP Files
A deep dive into the architecture behind on-demand container loading, explaining how AWS uses chunk-level deduplication, convergent encryption, and lazy fetching to slash Lambda cold starts.

Imagine you have to start 15,000 fresh containers per second, for a single customer, and each one might be backed by a 10GiB image. Multiply it out and you’d need 150 petabits per second of network bandwidth just to move the bytes, even before a single line of the customer’s code has run.
That’s the wall AWS Lambda hit when it decided to support container images. Lambda had built its reputation on cold starts as fast as 50ms. Customers wanted to bring Docker-sized dependency trees. Those two things, on the surface, don’t coexist.
The paper On-demand Container Loading in AWS Lambda (Brooker, Danilov, Greenwood, Piwonka) is the story of how the Lambda team reconciled them. They did it not by moving data faster, but by figuring out how to avoid moving most of it at all.

What Problem Was AWS Solving?
When Lambda launched in 2015, functions were uploaded as zip files capped at 250MB. Simple: download the archive, unpack it, run the code. It worked because the archives were small and the whole thing could be shipped and unzipped before the MicroVM needed to do anything.
By 2020, customers wanted more. They wanted to bring entire container images (up to 10GiB) built with normal Docker tooling, full of ML libraries, native dependencies, whatever their application needed. That’s a 40x jump in payload size, applied to a system that already had to spin up new capacity thousands of times a second while keeping start times in the tens of milliseconds.
Naively downloading and unpacking a full image per MicroVM doesn’t scale. So the real question the team faced wasn’t “how do we support bigger files”. It was:
How do we let customers ship anything up to 10GiB, without making a single container start ever have to move 10GiB?
Why Brute Force Wasn’t an Option
The obvious approach would be to download the image, unpack it, boot and that is exactly what the original zip-based system did, and it’s exactly what breaks at container scale.
At 15,000 new containers per second, even modest per-container downloads compound into unmanageable network and storage load. And the team wasn’t just fighting bandwidth. They were fighting unnecessary work: most of what’s inside a 10GiB image is never touched during a typical invocation. Prior research the authors cite found that on average only 6.4% of container data is needed at startup.
So the system doesn’t just need to move data faster. It needs to avoid moving data the function will never read.
The Core Insight
The paper’s architecture rests on three empirical properties of real-world Lambda usage, which the authors call out explicitly:
Cacheability: a small number of images drive most of the scale-up spikes, so the hot set is small relative to the total corpus.
Commonality: huge numbers of images share the same base layers (official Alpine, Ubuntu, Node images, AWS’s own base layers), so there’s enormous overlap between “different” images.
Sparsity: most of an image’s bytes are never touched at startup.
Put together, these three properties suggest the same conclusion from three different angles: you don’t need to move a 10GiB image per container start. You need to move the small, shared, frequently-reused slice of it that’s actually requested, and you need to do that at the block level, not the file level.
That’s the whole design in one sentence: flatten the image once (at deploy time, which is rare), chunk it, deduplicate the chunks across the fleet, cache the popular ones aggressively, and load only the blocks the guest kernel actually asks for, on demand, over a virtual block device.
Everything else in the paper, the encryption scheme, the garbage collector, the erasure coding, exists to make that one sentence work safely and fast at Lambda’s scale.
The Tradeoff
Most systems that accelerate container startup work at the filesystem level. That’s what Slacker and Starlight do: they lazily load individual files or layers as they’re needed, which is a natural fit because containers are already built as stacked, overlaid archives.
AWS deliberately didn’t do that.
They chose to keep the boundary between the MicroVM guest and the hypervisor at the raw block device layer (virtio-blk) and push all filesystem logic inside the untrusted guest, rather than exposing filesystem semantics to shared host-side components.
Why give up the natural fit? Security. The authors state plainly that layering multiple filesystems and understanding filesystem semantics on the trusted side of the boundary would unacceptably widen the attack surface of components shared across customers. A block device is a much simpler, better-understood interface to expose across a trust boundary than a filesystem.
The tradeoff:
Less semantic richness at the loading layer, in exchange for a smaller, simpler, more auditable attack surface.
To make block-level loading work without filesystem awareness, they had to do something clever at deploy time: deterministically flatten the whole OCI image, including every stacked tarball layer, into a single ext4 filesystem using a custom deterministic filesystem implementation (no concurrency, no random timestamps). As a result, identical file content always produces identical blocks. That determinism is what later makes chunk-level deduplication possible without any central index.
Architecture
The system splits cleanly along the same fault line as the rest of Lambda: a low-rate, per-function control plane step (image creation), and a high-rate, per-invoke data plane step (loading).
At function creation (whenever a customer pushes new code, rare, maybe a few times a minute across all of CI/CD):
The container image is pulled from the registry.
It’s deterministically flattened into an ext4 filesystem image.
That filesystem is chopped into fixed 512KiB chunks.
Each chunk is content-addressed, encrypted, and uploaded to S3 (the “origin tier”) if it doesn’t already exist there.
At invoke time (up to 15,000 times a second, per customer):
A new MicroVM boots against a FUSE-backed virtual block device.
As the guest kernel and customer code read files, those reads become block requests.
A local agent on the worker serves those requests from a per-worker cache if possible.
On a local miss, it pulls the chunk from an availability-zone-level distributed cache.
On a cache miss there too, it falls back to S3, the origin of last resort.
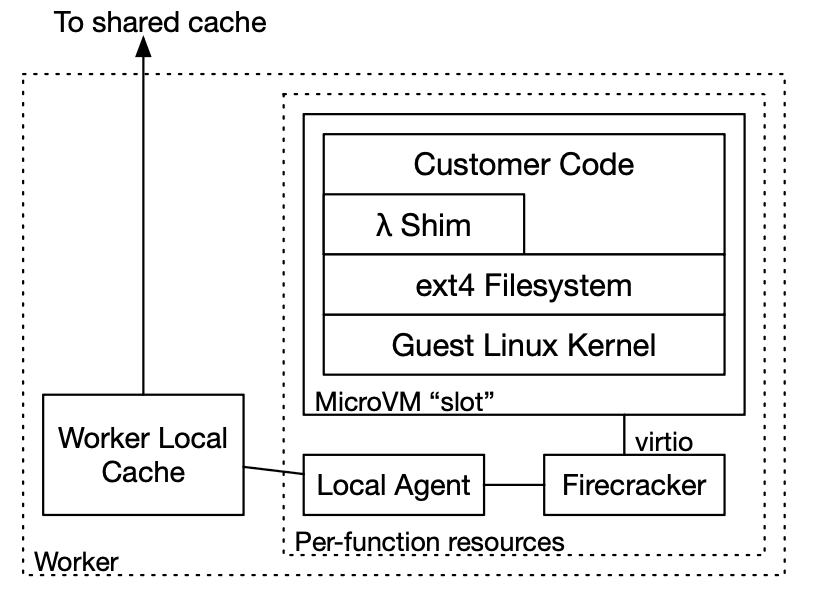
The result: image creation is expensive-ish but rare, and invocation is cheap because it only ever touches the handful of chunks a given execution actually needs, most of which are already sitting in a cache somewhere because thousands of other customers’ functions share the same base-image chunks.
Deduplication Without Trust
This is the part of the paper I found most interesting, because it solves a problem that sounds contradictory: deduplicate data across mutually-untrusting customers, without ever sharing an encryption key between them.
Encryption is supposed to make ciphertext look random. Deduplication depends on identical plaintext producing identical, comparable data. Those two goals fight each other. The same content encrypted under two different keys produces completely different ciphertext, so you lose your dedup signal the moment you encrypt normally.
AWS’s answer is convergent encryption, an idea that traces back to the Farsite paper from 2002. It derives the encryption key for a chunk from the chunk’s own content (its SHA256 digest), rather than from a customer’s private key. Identical content anywhere in the fleet converges on the identical key, and therefore the identical ciphertext, which is exactly what dedup needs, without any two customers ever having to share a secret.
The per-customer secret still exists, but its job is narrower, it encrypts the manifest (the map of chunk names and keys for a given image), not the chunks themselves. That means a garbage collector can walk the list of chunk names in a manifest without ever having the keys to decrypt their contents, a nice separation of duties.
The payoff, measured in production: approximately 80% of newly uploaded Lambda functions result in zero unique chunks, being re-uploads of previously seen images, largely driven by CI/CD systems, while the remaining 20% that do introduce new content have a mean of only 4.3% unique chunks and a median of 2.5%. That’s a huge amount of redundant data that never has to be stored, moved, or cached twice.
Because widely-shared chunks also mean widely-shared blast radius (corruption or a bad cache node affecting one popular chunk could ripple across many customers), they deliberately weaken deduplication on purpose sometimes, mixing a rotating salt into the key derivation so that otherwise-identical chunks can be forced to diverge across time or availability zones, trading some dedup efficiency for smaller failure domains.
Failure Handling: Garbage Collection as the Scary Part
The authors are refreshingly candid that the riskiest part of this whole system isn’t loading, it’s deleting. Get garbage collection wrong in a deduplicated store and you can silently destroy another customer’s data.
Imagine two customers upload different container images:
Image A
Manifest A
├── Chunk A
├── Chunk B
└── Chunk C
Image B
Manifest B
├── Chunk B
├── Chunk D
└── Chunk ENotice that Chunk B is shared. Thanks to deduplication, Lambda stores only one copy of it.
Now suppose Customer A deletes Image A.
Can AWS delete Chunk B?
No, because Image B still references it.
At Lambda’s scale, keeping an exact reference count for billions of chunks would mean constantly updating metadata whenever images are created, deleted, or rewritten. Those updates would become one of the busiest and most failure-prone parts of the storage system. Worse, a single incorrect reference count could cause live customer data to disappear.
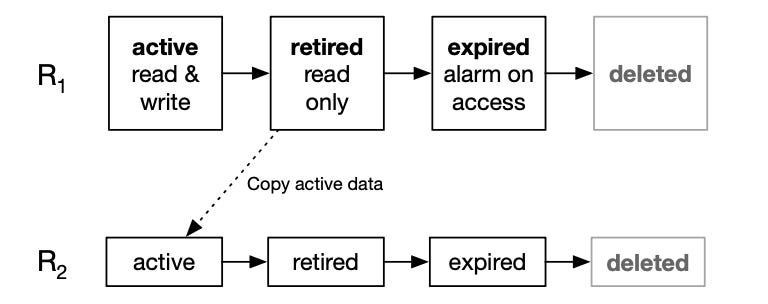
Rather than maintaining a central reference-counted index of every chunk (which they consider both complex and uniquely dangerous, given how quickly a live reference graph changes), they use a generational, root-based scheme.
Initially, all converted images are written into an active root:
Root R1 (Active)
Manifest A ──► Chunk A
├► Chunk B
└► Chunk C
Manifest B ──► Chunk B
├► Chunk D
└► Chunk EAfter some time, AWS creates a new active root.
Root R1 (Retired, Read-Only)
Manifest A
Manifest B
-------------------------
Root R2 (Active)
(new images go here)From this point onward, no new writes ever go into R1.
Now imagine Customer B still actively uses Image B.
Instead of keeping Manifest B in the old root forever, Lambda copies both the manifest and every chunk it references into the new root.
Root R2
Manifest B
├── Chunk B
├── Chunk D
└── Chunk EOnce every still-live image has been migrated, nothing in R1 is needed anymore.
Instead of asking:
Can I delete Chunk A?
Can I delete Chunk B?
Can I delete Chunk C?
AWS simply asks:
Can I delete Root R1?
If the answer is yes, millions of chunks disappear in one operation.
This turns garbage collection from tracking billions of individual references into deleting entire storage generations.
One subtle detail makes this work. Once R2 becomes active, newly uploaded chunks are not allowed to deduplicate against chunks in R1. AWS includes the active root’s identifier in the deduplication salt, ensuring that identical uploads create new chunks inside R2 rather than reusing chunks from older roots.
Without this, a new image in R2 could accidentally reference data stored in R1:
Root R2
Manifest X
│
▼
Chunk B (stored in R1)Now R1 can never be deleted because the newest generation still depends on it. By restricting deduplication to the active root, every root remains self-contained and can eventually be reclaimed.
The safety mechanism I liked most comes at the very end of the lifecycle. Instead of deleting a retired root immediately, AWS first marks it expired. An expired root is still readable, but any read immediately raises an alarm and automatically halts further deletion. It’s essentially a tripwire.
The protection isn’t perfect, a read could arrive milliseconds before the alarm propagates, but it transforms the failure mode from silently deleting live customer data into an automatically interrupted operation that engineers can investigate before more damage occurs. For a storage system serving millions of customers, that’s exactly the kind of failure mode you want: loud, observable, and recoverable instead of silent and irreversible.
What Breaks First? Tail Latency, Not Bandwidth
Once you accept that most reads will hit a cache, the next question is: what happens when a cache node is merely slow, not down?
The authors argue this is actually the harder problem operationally, since debugging partial slowness is harder than debugging outright failure, and it’s magnified by how many chunks a single container start touches. If a start needs 1,000 chunks, it will experience the cache’s 99.9th-percentile latency on 63% of tasks, simply due to how many independent draws it’s making.
Rather than the standard fix (replicate data, send redundant requests, eat the extra cost), they reach for erasure coding, following a similar approach to EC-Cache. In production they run a 4-of-5 code: any chunk fetch requests slightly more stripes than strictly necessary and reconstructs as soon as enough arrive, at a cost of roughly 25% extra storage and request volume, in exchange for much better tail latency than either a bare single-copy cache or full replication would give at the same cost.
They also explicitly avoid retry-based masking of slow or failed nodes, because retries under load are a known trigger of metastable failure. Erasure coding lets them do a fixed, predictable amount of work per request regardless of whether things are going well or badly, a philosophy they call “constant work.”
The Numbers That Made It Real
A few figures from the paper stood out:
On-worker cache hit rate: a median of 67%, with a 10th-percentile low of 65% over a week of production traffic.
AZ-level cache hit rate on top of that: a median of 99.9%, with a 10th-percentile low of 99.4%.
Overall, across a full week in one large AWS region: a median of 67% of chunks served from the on-worker cache, 32% from the AZ-level cache, and just 0.06% from S3, the backing store.
Latency difference between a cache hit and an S3 fetch: a median of 550 microseconds versus 36 milliseconds, roughly 65x, with the gap widening at the tail, 3.7ms versus 175ms at p99.9.
Deduplication’s storage impact: as much as a 23x reduction for functions that do introduce unique content, and another 5x on top of that from the 80% of uploads that are pure re-uploads.
The headline result, though, is less a number and more a design philosophy: the system was built so that an empty cache (from a power event, a bad deploy, whatever) doesn’t cascade into an outage. Because a cache running at 99.8%+ hit rate normally means a cold cache could throw 500x the usual traffic at S3, they deliberately bound blast radius with concurrency limits, and they actually test cold-cache starts at max concurrency rather than hoping it never happens.
Why This Paper Matters Beyond Lambda
A lot of container-loading research (Slacker, Starlight, eStargz, DADI, FaaSNet) attacks the same underlying problem: don’t ship the whole image, ship what’s needed, when it’s needed. What makes this paper worth reading even if you’ll never build a FaaS platform is the pattern, not the specific system:
Sparsity, commonality, and cacheability are properties you can probably find in your workload too, and each one independently suggests a different lever (don’t-move-what-isn’t-read, dedup-what’s-shared, cache-what’s-hot).
Security constraints can and should shape your architecture more than performance constraints do. The choice of block-level over filesystem-level loading here is a security decision dressed up as a performance one.
Deduplication and encryption aren’t actually opposed if you’re willing to derive keys from content instead of holding them centrally, a trick worth remembering any time “encrypt everything” and “don’t store duplicates” show up in the same set of requirements.
The scariest failure mode in a system like this usually isn’t the hot path. It’s the one place you delete data. Design that path to fail loudly and slowly, not silently and fast.
The team also underlines a broader lesson worth stealing directly: multi-modal latency distributions (local hit, remote hit, cold fetch) are the norm in storage systems, and single summary statistics, even percentiles, tend to hide that shape. If your system has more than one path a request can take, plotting the empirical CDF will usually tell you more than another dashboard full of p50/p99 numbers.
My Takeaways
What stuck with me most is how much of this paper is about not moving data rather than moving it faster. The team had every incentive to just throw more bandwidth or more caching hardware at the problem, and they still needed caching, still needed erasure coding, but the foundational move was architectural: flatten once, chunk small, dedupe hard, load lazily. Every optimization after that is amplifying a decision made long before the first byte crosses a network link.
The other thing worth sitting with: they chose Rust for a brand-new, security-critical, performance-critical component inside a system that already had Java, Go, and C in its invoke path, and their honest accounting of it includes a genuinely strange autovectorization bug that cost them real engineering time. It’s a useful reminder that “we picked the safe, fast language” doesn’t mean the compiler always cooperates; even well-established toolchains have sharp edges that only show up under production-grade optimization pressure.
Twenty-plus years after Venti and Farsite first explored content-addressed deduplication, this paper is a good demonstration that those old ideas aren’t just academic history. They’re still the right tool when you’re facing down a genuinely new scale problem, as long as you’re willing to rebuild the trust model around them for a new environment.