

Beyond the DLQ: What Really Happens After a Message Fails
How to transform Dead Letter Queues into a source of resilience and learning

Dear readers,
I still remember the moment clearly. I was in the middle of presenting a design for a new event-driven system. I had my architecture diagram up, services, topics, retries, and yes, a neat little Dead Letter Queue (DLQ) sitting off to the side.
One of the staff engineers raised a hand and asked me a simple question:
“Once a message is sent to the DLQ, then what? How do you actually know what the issue is?”
For a second, I froze. I had accounted for retries. I had thought about scaling. I had made sure failures wouldn’t break the main pipeline. But I realized I hadn’t thought deeply about what happens after something lands in the DLQ.
That question stuck with me. Because the truth is, in many system designs, a DLQ is treated like a checkbox. We draw it in the diagram, it gives a sense of safety, and we move on. But if you’ve ever actually operated such a system, you know that a DLQ is not the end of the story—it’s the beginning of one.
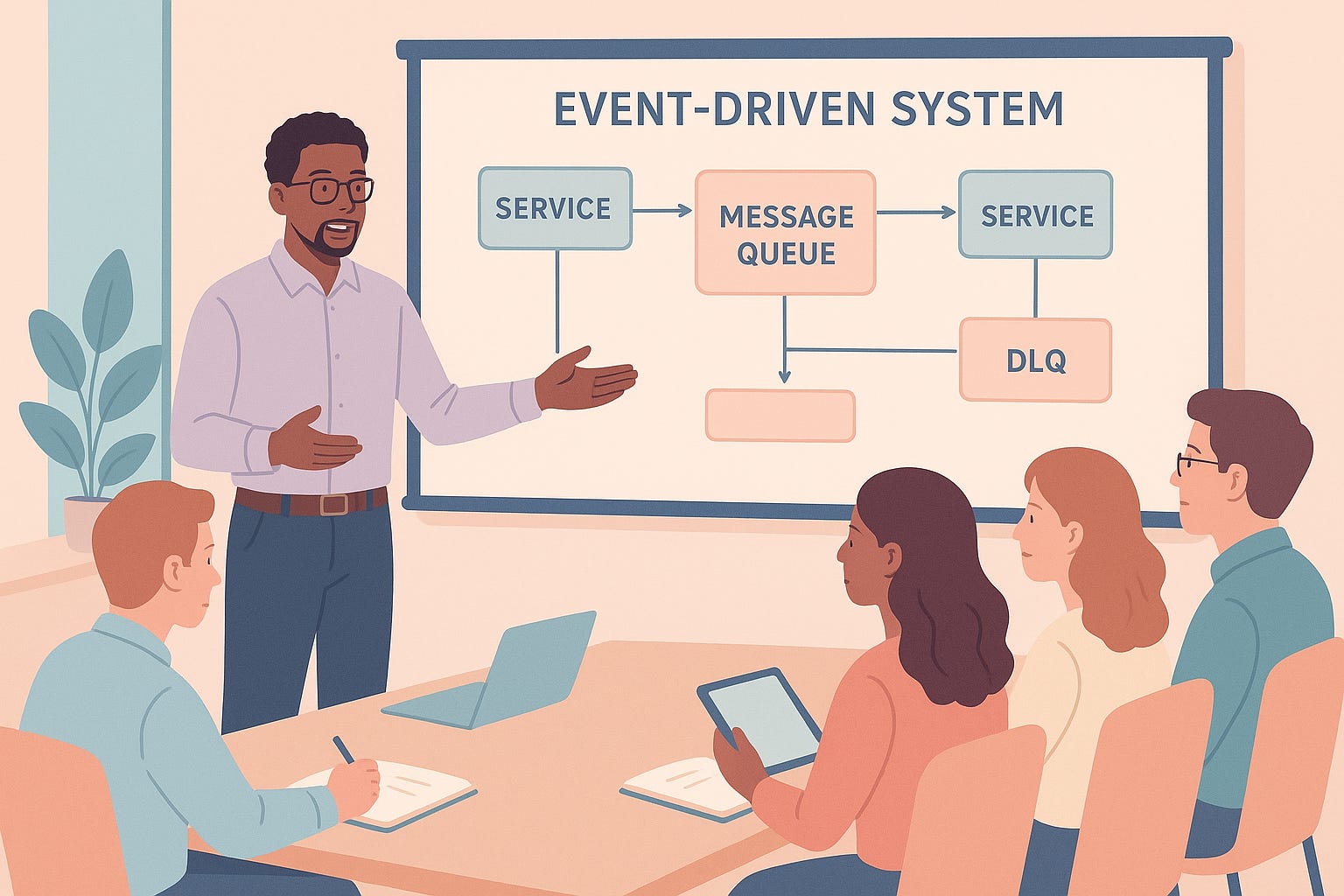
The Day We Lost Data Quietly
Not long after that presentation, I had my wake-up call.
One of our downstream services had made a schema change. The main queue retried the failing messages, but the consumers could not process them anymore. Eventually, those messages were moved into the DLQ.
And then nothing happened.
There was no alert. There was no dashboard entry calling attention to it. The DLQ sat quietly in the background, collecting failed messages that nobody was watching.
Two weeks later, those messages expired because in AWS SQS, DLQs automatically purge messages after fourteen days. By the time someone noticed missing data in a downstream report, it was gone forever. We had no way of knowing what the payloads were, no trace IDs, no metadata. Just silence.
That incident drove home a painful lesson: DLQs do not save you. They only delay the inevitable. Unless you monitor them and act, they become silent data graves.
So, What Is a DLQ?
Think of a DLQ like the “Lost and Found” counter at an airport. When baggage gets misplaced, it doesn’t vanish, it shows up at the counter. But if no one ever checks the counter, or if the bag doesn’t have a proper tag, it’s almost as good as lost.
That’s what happens in many systems. Messages that can’t be processed get pushed into the DLQ. They sit there quietly, like unclaimed baggage, until someone eventually notices there’s a growing pile of them. By then, the real issue, bad data, a downstream failure, or a misconfiguration, may have already caused damage.
So the real question isn’t do you have a DLQ? It’s what do you do with it?

The Questions We Rarely Ask
Looking back, I realized that my original design doc never asked the right questions:
What happens when a message actually lands in the DLQ?
Do we consume and log it anywhere permanent?
Should metadata, like error type, trace ID, and timestamp be attached so engineers can diagnose the cause?
Who owns the DLQ, and how quickly should they act when it fills up?
How do we prevent silent expiration?
Without answers, the DLQ is just a checkbox. It exists, but it does not help.
Poison Pills and Infinite Loops
Later, I ran into another problem: the poison pill message.
This is the message that can never succeed. Perhaps the payload is malformed beyond repair, or the downstream service rejects it permanently.
At one point, we had such a poison pill bouncing endlessly between the main queue and the DLQ because of a naive “automatic redrive” process. Every time it was replayed, it failed in the same way.
Instead of healing the system, our DLQ had turned into a loop of repeated failure. That was the moment I realized: redrives must never be blind. You need context. You need human eyes or smart triage before you send a message back into the system.
Turning DLQs Into Debugging Tools
The breakthrough came when we stopped treating DLQs as storage and started treating them as debugging pipelines.
Instead of dumping raw payloads, we enriched every DLQ message with structured metadata:
Error category (validation error, downstream failure, business rule violation)
Originating service
Retry count
Trace or correlation ID
Timestamp
Now, when a message appeared in the DLQ, engineers could immediately understand why it was there. We had transformed the DLQ from a black box into a window into system health.
From DLQ to PLQ: A Permanent Record
Even with metadata, DLQs came with another limitation: expiration.
We solved this by creating what we called a Parked Letter Queue (PLQ), a database-backed error log that stored all failed messages, enriched with context.
The way I like to describe it is that the DLQ is like the emergency room: temporary, chaotic, and focused on urgent triage. The PLQ is the hospital’s archive: a permanent record of every case.
With the PLQ, we finally had:
A searchable history of failures
An audit trail for debugging and compliance
The ability to identify recurring failure patterns over time
That single addition meant we no longer woke up to missing data with no explanation.
A Simple Analogy
Imagine a conveyor belt in a factory. Most items pass through fine, but occasionally one is defective. Instead of halting the belt, the item is pushed into a reject bin, that is your DLQ.
Now imagine if no one ever checks the reject bin. Products keep disappearing, and nobody knows why.
But if every defective item is labeled with why it failed, which machine broke, and at what time, and those labels are logged in a permanent book, you start to see patterns. Maybe Machine A jams every Monday. Maybe Supplier X always ships faulty parts. Suddenly, the reject bin is not just waste; it is a source of insight.
That is how DLQs should be treated.
Designing DLQs That Actually Help
From these experiences, I realized that a DLQ isn’t just a “safety bucket”, it’s a tool for learning, accountability, and resilience. But that only works if it’s designed with intention. Here are some principles that have stuck with me:
1. Monitor them like you mean it.
A DLQ that no one watches is just a black hole. Track not only how many messages land there (depth), but also how long they’ve been sitting (age) and how fast new ones are arriving (throughput). A sudden spike could mean a broken deployment. A slow accumulation might indicate a silent data quality issue. Alerts on these metrics often become your first signal that the system is quietly burning.
2. Enrich messages with metadata.
A raw payload alone is often meaningless at 3 AM when you are debugging. Include trace IDs, service names, timestamps, error codes, or even a short reason for failure. Think of it as leaving breadcrumbs for your future self (or the unlucky teammate on call). The easier it is to reconstruct the story of “what went wrong,” the faster you can fix it.
3. Redrive with discipline, not desperation.
The temptation is to just shovel DLQ messages back into the main queue once the pipeline looks healthy again. That’s risky. If the root cause hasn’t been fixed, you’re just replaying the same movie. Instead, validate fixes, test carefully, and only then reintroduce messages. Redriving should be a controlled process, not a panic button.
4. Consider a PLQ or permanent error log.
DLQs often have retention limits. If you don’t act in time, your evidence just expires. A Parked Letter Queue (PLQ) or dedicated error store solves this by keeping failed messages along with all the metadata, forever if needed. It becomes the system’s diary of failures, a reliable record you can revisit for audits, debugging, or even training better validation rules.
Final Reflection
That simple question during my design presentation, “Once a message is sent to the DLQ, then what?” was one of the most valuable lessons of my career.
DLQs are not the end of the story. They are the beginning of an investigation. They are not insurance policies; they are mirrors reflecting where your system is fragile.
The real measure of resilience is not whether you have a DLQ. It is whether you know what is inside it, and whether you are doing something about it.
If you would like me to share a guide on how to implement DLQs effectively, whether on AWS SQS, Google Pub/Sub, or Kafka, drop a comment below.
Great read Rahul , Would love to know the implementation of DLQ for Kafka/Google Pub Sub .
Keep up the good work !