

Google MapReduce Architecture Explained: Lessons Every Backend Engineer Should Learn
The paper that made failure, scheduling, and scalability someone else's problem

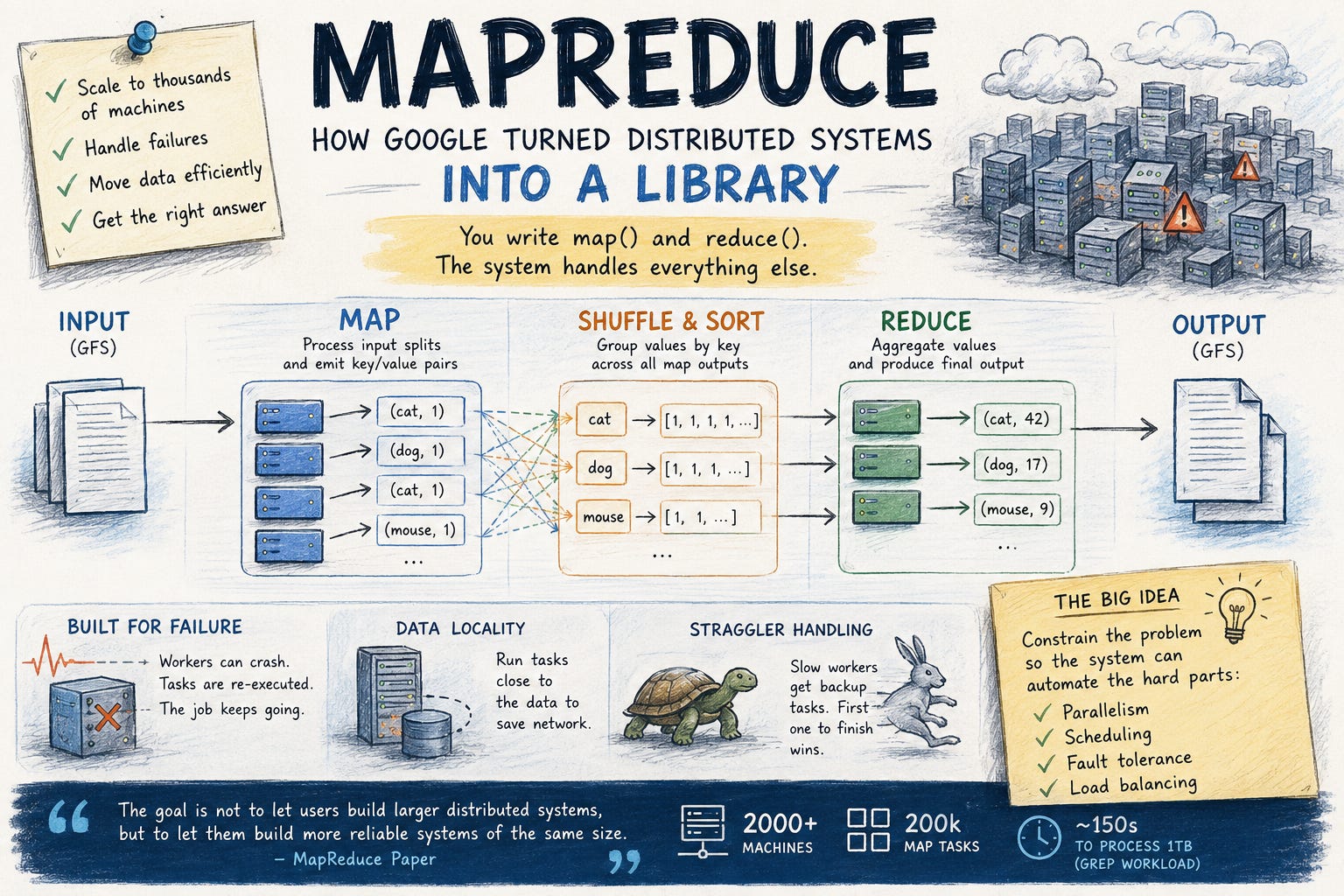
Imagine being asked to process a terabyte of data across thousands of machines. Some servers crash halfway through execution. Others become painfully slow. Network links saturate. Disks fail. And despite all of that, the final result still needs to be correct.
Today, we take it for granted that distributed systems platforms handle these problems for us. Frameworks automatically retry failed tasks, rebalance workloads, and recover from machine outages. But in the early 2000s, none of this was standard.
If you wanted to process data at scale, you often had to build a distributed system before you could even begin solving your actual business problem. Engineers had to think about machine placement, scheduling, partitioning, fault tolerance, retries, and data movement long before they wrote the logic they actually cared about.
The first time I read Google’s MapReduce paper, I was surprised by how little of it is actually about computation. Most of the paper is about failure, coordination, and moving data efficiently. More than twenty years later, those are still the same problems that dominate large-scale distributed systems.
Google’s insight was deceptively simple: what if developers didn’t need to think about any of that?
Instead of asking engineers to build distributed systems, MapReduce asked them to write just two functions: map() and reduce(). Everything else like scheduling, fault recovery, parallelization, load balancing, and data movement became the platform’s problem.
That single idea changed how the industry thinks about large-scale data processing.
What Problem Was Google Solving?
In the early 2000s, Google’s growth created a problem that traditional software architectures simply couldn’t handle.
Search indexing, log analysis, web crawling, and machine learning workloads required processing enormous datasets across clusters containing thousands of commodity machines. Running these jobs wasn’t particularly difficult when everything worked perfectly.
The real challenge was that everything rarely worked perfectly.
At Google’s scale, machine failures were routine. Disks failed. Network links slowed down. Some servers disappeared in the middle of execution, while others became unexpectedly slow. The larger the cluster became, the more likely it was that something would go wrong during every job.
Most distributed systems at the time treated failures as exceptional events. Google had reached a scale where failures had become part of normal operation.
This created a much deeper problem than simply processing large amounts of data.
Every team that wanted to analyze data effectively had to become experts in partitioning, scheduling, fault tolerance, retries, load balancing, and data movement. The business logic was often the easy part. Building the distributed system around it was the hard part.
Google’s question wasn’t:
How do we process a terabyte of data?
It was:
How do we make large-scale data processing accessible to normal engineers without forcing them to become distributed systems experts?
MapReduce was Google’s answer.
Why Existing Approaches Were Not Enough
Before MapReduce, every large-scale data processing job effectively became its own distributed system.
Suppose a team wanted to count words across billions of documents or analyze terabytes of logs. The computation itself was often straightforward. The hard part was everything around it.
Engineers had to figure out how to partition data across machines, schedule work efficiently, recover from failures, handle slow workers, balance load, and coordinate execution across the cluster. Application code quickly became tangled together with infrastructure concerns.
The actual business logic often represented only a small fraction of the overall implementation.
As clusters grew larger, the problem became even worse. More machines meant more failures, more network traffic, and more coordination overhead. Teams repeatedly solved the same distributed systems problems for every new data-processing application they built.
What’s interesting is that computation itself was rarely the bottleneck. The real challenge was coordination.
Moving data across the network, recovering from failures, balancing workloads, and ensuring correctness consumed far more engineering effort than the computation being performed.
Google noticed something important: many of these applications followed a similar execution pattern. If that common pattern could be standardized, the distributed systems complexity could be built once and reused everywhere.
Instead of every team building its own distributed system, Google could provide a framework that handled the hard parts automatically.
That realization eventually became MapReduce.
The Core Insight
The breakthrough behind MapReduce wasn’t a new algorithm. It was a new abstraction.
Google realized that many large-scale data processing jobs, despite looking very different on the surface, followed a remarkably similar pattern. Data was read, transformed into intermediate results, grouped by some key, and then aggregated into a final output.
MapReduce turned that pattern into a programming model.
Developers only needed to describe their computation using three stages:
Map → Shuffle → ReduceAt first glance, this seems like an unusually restrictive way to write software. But that restriction is precisely what gives the system its power.
Once the runtime knows that every job follows the same execution pattern, it can take responsibility for everything else. It can automatically parallelize work across thousands of machines, schedule tasks efficiently, move computation closer to data, recover from failures, retry lost work, and rebalance slow workers.
The developer focuses on the problem they are trying to solve.
The platform focuses on running that computation reliably at scale.
What makes this idea so powerful is that it changes the role of the programmer. Instead of building a distributed system for every new application, developers simply describe the computation they want to perform. The infrastructure takes care of the rest.
That separation between business logic and distributed systems complexity became one of the most influential ideas in modern infrastructure.
The Tradeoff
The brilliance of MapReduce comes from what it deliberately refuses to do.
Most distributed systems try to be flexible. They provide developers with powerful primitives and let them decide how computation should be executed across machines.
MapReduce takes the opposite approach.
Instead of supporting every possible distributed computation, it asks a much simpler question:
What if we only support the subset of problems that fit the Map, Shuffle and Reduce model?
At first glance, that sounds limiting.
And it is.
MapReduce gives up many capabilities that developers might want. There is no arbitrary communication between tasks. There is no fine-grained control over execution. Stateful iterative workloads are difficult to express. Complex dependency graphs don’t fit naturally into the model. Low-latency processing isn’t a design goal.
But those limitations are exactly what make the system powerful.
Because the runtime understands how every job behaves, it can automate much of the complexity that normally falls on developers. Scheduling, fault recovery, load balancing, task placement, retry logic, and parallel execution all become infrastructure concerns rather than application concerns.
The tradeoff is simple:
Less flexibility for the programmer. More leverage from the platform.
What MapReduce sacrifices in generality, it gains in simplicity, scalability, fault tolerance, and operational reliability.
What’s remarkable is how often this idea appears in modern systems.
At Wayfair, most engineers don’t think about leader election, partition recovery, retry coordination, or distributed consensus when building services. Platform teams and infrastructure abstractions handle those concerns. Developers focus on business logic.
MapReduce was one of the earliest and most influential examples of this philosophy. Instead of asking every team to become distributed systems experts, it pushed complexity downward into infrastructure where it could be solved once and reused everywhere.
In many ways, that idea became the blueprint for modern platform engineering.
Architecture
One reason MapReduce became so influential is that the architecture mirrors the programming model itself.
Every component exists to support one of three stages: Map, Shuffle, or Reduce. There are surprisingly few moving parts, yet together they solve some of the hardest problems in distributed systems, task scheduling, fault tolerance, parallel execution, and data movement across thousands of machines.
What’s remarkable is how much complexity is hidden behind such a simple interface. Developers see two functions. Underneath, an entire distributed execution engine coordinates work across the cluster.
At a high level, the architecture looks like this:
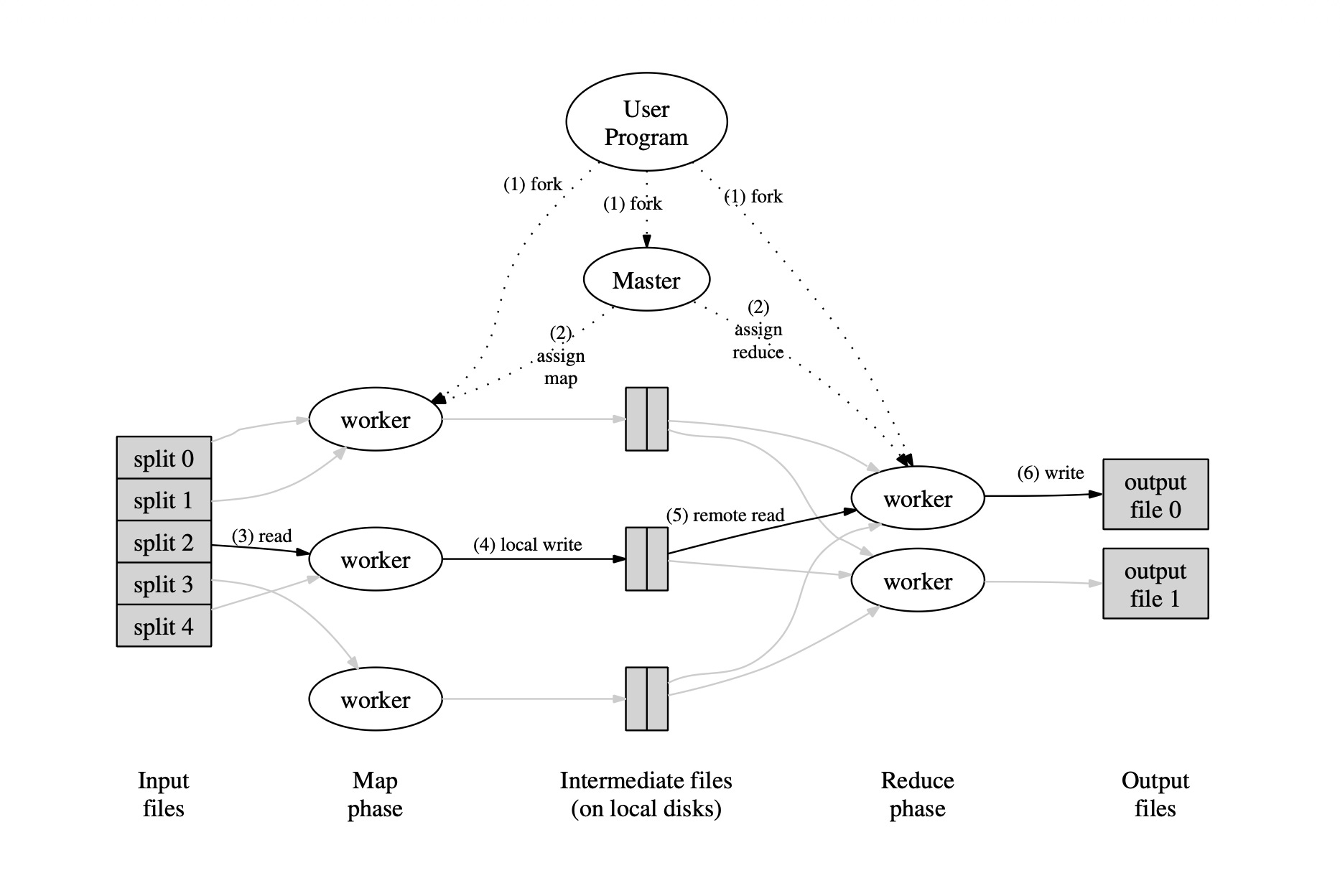
Input data lives in Google’s distributed file system and is divided into smaller chunks. Map workers process those chunks independently and emit intermediate key-value pairs.
Those intermediate results are then partitioned by key and stored locally. During the shuffle phase, reduce workers fetch the partitions they need from every mapper, sort them, group values belonging to the same key, and execute the reduce function to produce the final output.
Simple in concept.
Remarkably powerful in practice.
In many ways, the architecture embodies the central idea of the paper: developers describe the computation, while the platform takes responsibility for everything required to execute that computation reliably at scale.
Example: Word Count
The classic example is counting word frequency.
Suppose you have billions of documents and want to know how many times each word appears.
Map
Each worker emits:
("chair", 1)
("sofa", 1)
("chair", 1)
("lamp", 1)Shuffle
The system groups identical keys together:
("chair", [1,1,1,1,...])
("sofa", [1,1,...])
("lamp", [1,1,1,...])Reduce
Reducers aggregate the values:
("chair", 12849302)
("sofa", 8349201)
("lamp", 4419022)The programmer writes a few lines of logic.
The platform handles:
Splitting data
Scheduling work
Moving data
Recovering from failures
Handling slow machines
Writing final outputs
That was revolutionary.
MapReduce changed the unit of abstraction from:
Build a distributed pipeline
to
Write two functions.
Failure Handling
One of the reasons the MapReduce paper became so influential is how aggressively it embraces failure.
Many distributed systems are designed around the assumption that failures are exceptional events. MapReduce assumes the opposite. At Google’s scale, machine failures were not edge cases. They were part of normal operation.
The framework is built on a simple idea: failures should not require human intervention.
If a worker machine crashes halfway through a task, the system doesn’t panic. Workers are monitored through heartbeats, and missing workers are treated as failed. Any in-progress tasks are reassigned to healthy machines, lost map outputs are recomputed, and the job continues running.
Network failures are handled in a similarly pragmatic way. From the master’s perspective, an unreachable worker is indistinguishable from a failed worker. Rather than trying to determine the exact cause, the system simply reschedules the work elsewhere.
Even disk failures are treated as recoverable events. Since map outputs can be regenerated and input/output data is protected by the distributed file system, losing a local disk rarely threatens the overall job.
What’s interesting is that MapReduce doesn’t just prepare for machines that fail.
It also prepares for machines that survive.
In large clusters, some workers inevitably become slower than others. A handful of slow machines can delay an entire job, even when everything else is running perfectly.
To address this, MapReduce introduced one of the paper’s most influential ideas: speculative execution.
Near the end of a job, backup copies of slow tasks are launched on other machines. Whichever copy finishes first wins, while the remaining copies are discarded.
It’s a deceptively simple optimization, but it attacks a problem that still exists in modern distributed systems: tail latency. Often, the slowest machine determines when the entire job completes.
The one significant weakness in the design is the master node.
MapReduce relies on a single master to track task assignments, worker status, and job metadata. If that master fails, the job fails with it. The paper suggests checkpointing as a future improvement, but the implementation described does not fully eliminate this single point of failure.
What makes the design remarkable isn’t that it prevents failures.
It’s that it assumes failures are inevitable and builds recovery directly into the execution model.
That’s a philosophy that continues to influence distributed systems more than two decades later.
What Breaks First?
One of the things I appreciate most about the paper is how honest it is about scalability bottlenecks.
When engineers think about scaling a system, the first question is often:
Will we run out of CPU?
For MapReduce, the answer is usually no.
Most large jobs spend far more time moving data than computing on it. The computation itself is often the easy part. Coordinating thousands of machines and shuffling massive amounts of data across the network is where the real cost lies.
Memory can become a bottleneck, particularly on reducers. When intermediate datasets exceed available RAM, reducers spill data to disk and continue processing. Performance suffers, but the system remains functional.
The first major bottleneck is usually the network.
The shuffle phase dominates many workloads because data produced by map tasks must be transferred across the cluster before reducers can begin their work. In many ways, the architecture is optimized around a single goal: minimizing unnecessary network traffic.
Storage is another pressure point.
Large sorting jobs generate enormous amounts of disk I/O. Map workers continuously spill intermediate files to disk, while reducers read, merge, sort, and write large volumes of data. The system survives these workloads, but disk activity often becomes a limiting factor.
Even the control plane has its limits.
The master node tracks metadata for every map and reduce task using an O(M × R) data structure, where M is the number of map tasks and R is the number of reduce tasks. While this worked well at Google’s scale, it hints at a future bottleneck as clusters and workloads continue to grow.
What I find particularly interesting is that none of these bottlenecks are primarily about computation.
The paper repeatedly reinforces a lesson that still applies to modern distributed systems:
The hardest resource at scale is often not compute. It’s coordination.
Network traffic, data movement, scheduling decisions, and tail latency frequently matter far more than raw processing power.
The Numbers That Made People Pay Attention
What made this paper particularly convincing was that it included real production results.
A representative configuration included:
2,000 worker machines
200,000 map tasks
5,000 reduce tasks
Google demonstrated:
A 1 TB grep workload completed in roughly 150 seconds
A 1 TB sort completed in roughly 891 seconds
More importantly, they deliberately killed hundreds of machines during execution.
The result?
The sort job slowed by only about 5%.
That number captures the paper’s real thesis:
Failure is not an exception. Failure is a scheduling event.
Why MapReduce Changed the Industry
Many papers introduce useful ideas.
Very few change how an entire industry thinks about a problem.
MapReduce did.
Before MapReduce, large-scale data processing was often treated as an application problem. Every team that wanted to process massive datasets had to solve the same distributed systems challenges: task scheduling, fault tolerance, load balancing, machine failures, and data movement.
MapReduce changed the boundary.
Instead of asking application developers to solve those problems repeatedly, it pushed them into the platform. Developers described the computation they wanted to perform. The infrastructure handled everything else.
That shift turned out to be far more important than the Map and Reduce functions themselves.
Inside Google, teams could process enormous datasets without reinventing distributed infrastructure for every new application. Outside Google, Hadoop brought the same programming model to the broader industry and made large-scale data processing accessible to organizations that didn’t have Google’s engineering resources.
The influence of the paper extended far beyond Hadoop.
It established data locality as a first-class design principle. It popularized the shuffle phase as a fundamental building block of distributed computation. More importantly, it demonstrated that infrastructure could absorb complexity that applications previously managed themselves.
Even the systems that eventually replaced MapReduce were shaped by it.
Spark, for example, can be viewed partly as a response to MapReduce’s limitations. Excessive disk materialization, high latency, and weak support for iterative workloads motivated a new generation of data processing frameworks.
But Spark only makes sense in a world that MapReduce created.
The conversation shifted from:
How do we build distributed data processing systems?
to:
How do we build a better version of MapReduce?
That’s the mark of a truly influential idea.
The strongest evidence that MapReduce succeeded is that most engineers no longer think about the problems it solved.
Today, we expect platforms to recover from failures automatically, scale across clusters, rebalance slow workers, and schedule work intelligently. Those capabilities feel obvious because modern infrastructure provides them by default.
In 2004, they weren’t infrastructure problems.
They were application problems.
MapReduce helped change that.
More than twenty years later, most distributed data platforms are still following the blueprint it introduced: hide the complexity of distributed systems behind a simple programming model and let the platform do the heavy lifting.
My Learnings
The most valuable systems ideas often look like restrictions, not freedoms.
A narrow programming model can create extraordinary leverage if it allows the platform to absorb complexity.
After working on inventory systems that process hundreds of thousands of events per second, I’ve come to appreciate how true this observation is. CPU is usually easy to buy. Coordination isn’t. Network traffic, retries, partition ownership, and tail latency create far more production incidents than raw compute shortages.Network movement, scheduling decisions, data placement, and tail latency frequently matter more than raw processing power.
Most importantly, MapReduce shows that great infrastructure doesn’t necessarily make systems more powerful.
Sometimes it makes them simpler.
Google took one of the hardest problems in software engineering and reduced it to two functions.
More than twenty years later, most distributed data platforms are still following that blueprint.
The interesting question isn’t how Google built MapReduce in 2004. It’s how we would build it today. In the next post, I’ll walk through the architecture I’d choose in 2026, the components I’d replace, and the tradeoffs I’d make differently. Subscribe if you’d like to follow along.