

Why “Just Publish to Kafka” Almost Sank Our Service
How we went from 4-5 escalations per week to zero by adopting a simple but powerful pattern.

Dear readers,
It was 2:00 AM when one of our downstream services pinged us:
“Our system says a lane exists, but your APIs disagree. Which one’s right?”
Slack was on fire. Kafka showed a brand-new lane between two facilities, but when someone queried our service, the database claimed nothing had changed. Downstream systems were already processing this phantom lane.
That was the night we learned the hard way about dual transactions.
In this post, I’ll walk you through:
The problem with dual transactions: why Postgres and Kafka can easily fall out of sync.
How the Outbox Pattern works: the schema, publisher design, and flow.
Real-world debugging challenges we faced: stuck rows, duplicates, backlogs, and how we fixed them.
The role of BigQuery: how we used it for observability, debugging, and analytics.
Trade-offs and best practices: where Outbox shines, where it doesn’t, and a checklist if you want to adopt it.
Business impact: how we went from weekly 2 AM escalations to zero.

The World We Lived In
Our service was the source of truth for all facilities: warehouses, carrier hubs, depots, cross docks, suppliers. We also managed lanes, the entities connecting facilities.
The rules were simple but strict:
If a facility’s schedule changed, downstream needed to know.
If a lane opened or closed, downstream needed to know.
We used Postgres as the database and Kafka as the event bus. Updates had to land in both. And that’s where the nightmare began.
Dual transactions, Dual Headaches
Two failure modes haunted us:
DB succeeds, Kafka fails
Data saved in Postgres.
Event never published.
Downstream blind to reality.
Kafka succeeds, DB rolls back
Event goes out.
DB rejects transaction.
Downstream believes a lie.
Both cases left us with corrupt, unsynced worlds. We had dashboards in red, and multiple “let’s sync the facility and lanes data” firefights.
At our peak, this caused 4-5 escalations per week. After fixing it, escalations dropped to zero.
Enter the Outbox Pattern
Instead of trying to write to two systems atomically (which distributed systems hate), we decided to only trust one write path: the database.
Here’s how:
Write Once
Every DB transaction that modifies business data also inserts an event into an outbox table.
If the DB commit succeeds, both data + outbox entry are durable.
CREATE TABLE facility_outbox (
id BIGSERIAL PRIMARY KEY,
aggregate_type VARCHAR(50),
aggregate_id UUID,
event_type VARCHAR(50),
payload JSONB,
created_at TIMESTAMP DEFAULT now(),
processed BOOLEAN DEFAULT false
);Query-based CDC
A lightweight publisher job polls this outbox table.
It picks unprocessed rows, marks them, then pushes them to Kafka.
SELECT * FROM facility_outbox
WHERE processed = false
FOR UPDATE SKIP LOCKED
LIMIT 100;Mark as Processed
After a successful publish, mark rows as
processed = true.If publish fails, retry safely.
Now the DB was the single source of truth, and Kafka simply reflected it. No more split-brain.
Architecture at a Glance
Here’s what the flow looked like after Outbox adoption:
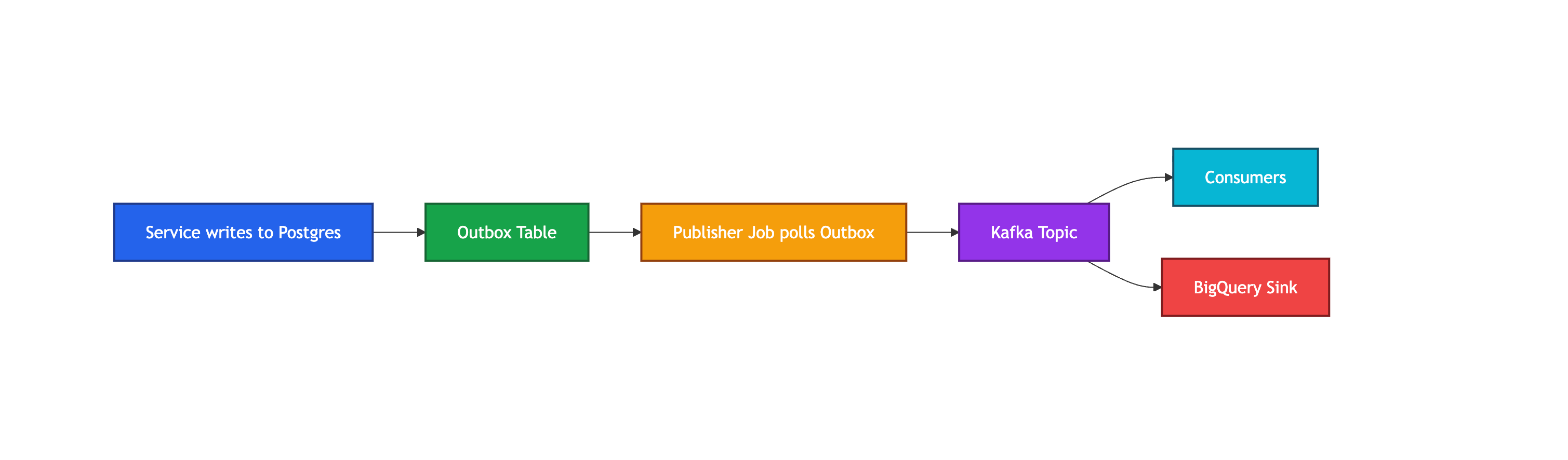
Debugging Nightmares We Solved
This wasn’t just plug-and-play. We hit plenty of edge cases:
1. Stuck Rows
Sometimes publishers crashed mid-batch.
Rows got locked forever.
Fix:
SKIP LOCKEDensured other workers could move on.
2. Duplicate Events
Retries led to re-publishing.
Solution: consumers became idempotent, keyed by
event_id.
3. Slow Publishers
Outbox grew faster than we could drain it.
Fix: batch publishes + horizontal scaling of publishers.
4. Backfill Hell
New systems wanted all historical events.
Answer: replay directly from the outbox table → no custom scripts.
Why BigQuery Sink?
We weren’t just worried about delivery—we also needed observability.
Every Kafka topic had a BigQuery sink.
This let us:
Run ad-hoc queries: “Show all lane updates in the last 6h.”
Debug mismatches: compare DB state vs. published events.
Prove SLAs: how fast events left the outbox.
It was our black box recorder for event history.
Trade-offs We Faced
The Outbox pattern isn’t a silver bullet. We had to weigh:
Extra DB Load: every change means an extra insert.
Latency: events are near-real-time, not instant (polling adds ~200–500ms).
Storage Growth: outbox table can bloat if not purged/archived.
Operational Complexity: need monitoring, retries, and cleanup policies.
But for us, consistency > absolute latency. We’d rather downstream be slightly late than totally wrong.
When to (and NOT to) Use Outbox
Use Outbox if…
Your service is a source of truth and must publish events reliably.
You’re dealing with critical entities (orders, payments, facilities, lanes).
Dual writes would cause corruption.
Don’t bother if…
Events are non-critical logs/metrics.
Latency requirements are microseconds.
You already have a rock-solid streaming CDC pipeline like Debezium.
Checklist for Adopting Outbox
Design outbox schema (include metadata + payload).
Use
FOR UPDATE SKIP LOCKEDto avoid stuck workers.Make consumers idempotent.
Add monitoring: queue size, lag, failed publishes.
Decide retention: archive or delete processed rows.
(Optional) Sink to BigQuery or warehouse for debugging.
Final Thought
After moving to Outbox, our 2 AM “facility lane mismatch” alerts vanished.
No more phantom lanes. No more split-brain facilities.
The system wasn’t perfect—there was extra DB load, and events weren’t instant. But consistency beat chaos.
And honestly? With Outbox in place, the only thing waking us up at 3 AM was the baby, not broken events. 👶✨