

The Secret to Netflix’s Lightning-Fast Counters
How distributed systems, batching, and eventual consistency make millions of increments possible every second.

Dear readers,
Counting sounds easy, right?
You add one number to another, maybe you keep a counter in a database or increment a value in memory. Simple.
But at Netflix’s scale, even something as basic as “counting” becomes a serious engineering challenge.
When you have millions of users streaming content every minute across thousands of servers distributed around the world, the act of “adding one more view” to a counter quickly turns into a distributed systems problem.
Let’s dive into what the problem was, why traditional methods fail, and what we can learn from how Netflix approached it.

The Problem: Counting at Netflix Scale
Imagine you are tracking how many people are watching Stranger Things right now.
Every time someone presses play, one counter somewhere needs to go up by one.
Now imagine this happening across hundreds of data centers, each handling its own share of users.
That’s millions of increments per second.
If you had just one database where all those servers sent an “increment” request (INCR), you would have:
A massive bottleneck with too many requests hitting the same database
Network delays and contention
Possible data loss if that central database crashes
And worst of all, your “total view count” could become inconsistent or outdated.
Netflix engineers needed a way to count accurately, fast, and reliably, even when data was spread across thousands of machines.
Why Traditional Counting Doesn’t Work
Let’s take the simple approach most of us use in smaller systems:
count = count + 1It works beautifully on a single machine. But the moment you distribute this logic across hundreds of servers, problems begin.
Concurrency Issues: Two servers might try to update the same counter at the same time, causing incorrect totals
Latency: The more servers that try to reach the central counter, the slower it gets
Failure Handling: What happens if one server crashes mid-update
Scalability: A single counter database cannot handle billions of updates per second
Netflix realized that instead of making one machine handle all counts, they needed each machine to count locally, and then combine those counts efficiently.
Netflix’s Solution: Decentralized, Event-Driven Counting
Here’s the key insight:
Do not count everything in one place. Let every server count independently and merge those results later.
This is called decentralized counting.
Each server does its own small counting for a short time window. Then, it sends those local totals, called deltas, to a central pipeline like Kafka.
Think of it like this:
Every store branch counts how many customers visited today
At the end of the day, each branch sends their total number to the head office
The head office adds all those branch numbers together to get the company-wide total
Netflix does exactly this, but continuously and in real time.
How It Works Step by Step
Local Counting
Each Netflix microservice instance keeps a small in-memory counter. It increments locally whenever a new event happens, like a stream start or a likeBatching
Instead of sending every single increment, each instance batches its counts for a short period, for example every few secondsPublishing
These batched counts are published to Kafka, Netflix’s distributed event streaming platformAggregation
A specialized service consumes these delta events and aggregates them by keys, for example show ID, region, or time windowStorage
The final aggregated counts are stored in a scalable database like Cassandra or Redis, which can handle huge read and write volumes
Handling Delays, Duplicates, and Failures
In distributed systems, you cannot assume everything arrives perfectly on time or only once.
Some deltas might get delayed due to network lag, and some might even get sent twice during retries.
Netflix solved this by designing their system to be idempotent, meaning even if the same update is applied twice, the result remains correct.
Each delta has:
A unique ID to detect duplicates
A timestamp window to know when the counts happened
The increment value for how much to add
Even if Kafka replays an event or a message is retried, the aggregator can safely ignore duplicates and apply counts correctly.
This ensures that the final global count is accurate, even if updates come late or in random order.
In-Depth Architecture
For those who’ve stayed with us this far, let’s dive deeper into the architecture. After evaluating multiple approaches, Netflix ultimately adopted a hybrid, event-driven solution for distributed counting. This final design strikes a careful balance between low-latency reads, high throughput, and strong durability.
1. Event Logging in TimeSeries Store
Every counter increment is treated as an immutable event and ingested into Netflix’s TimeSeries abstraction, which acts as the event store. Each event record includes:
event_time: Timestamp of the incrementevent_id: Unique identifier for idempotencycounter_nameandnamespace: To identify which counter it belongs todelta: The increment value (positive or negative)
The TimeSeries abstraction, typically backed by Cassandra, ensures high availability, partition tolerance, and fast writes. Events are partitioned using time_bucket and event_bucket columns to prevent wide partitions that could degrade read performance.
Benefits:
Immutable events prevent accidental data loss
Built-in retention policies automatically purge old events
Supports safe retries due to idempotency keys
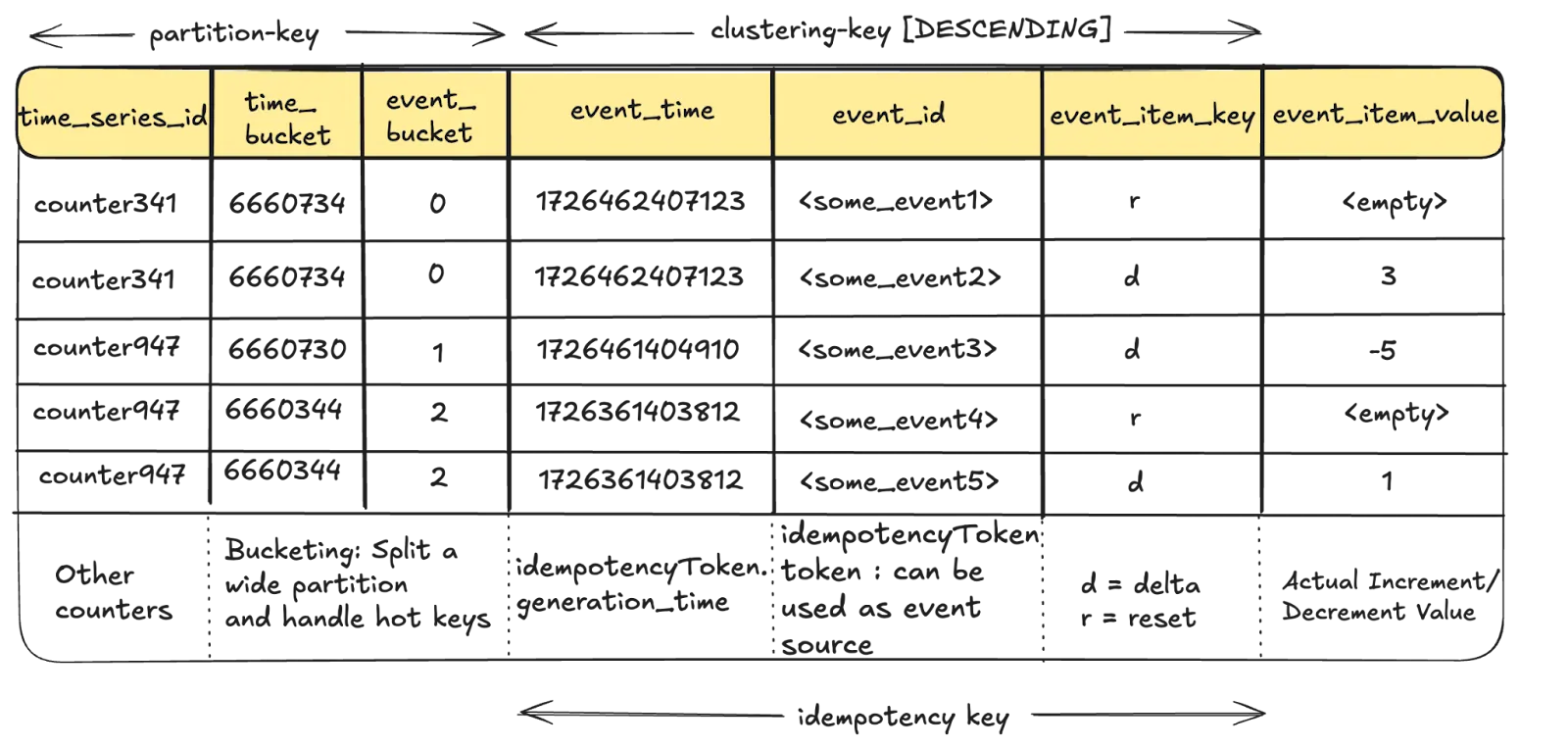
Handling Wide Partitions: The time_bucket and event_bucket columns play a crucial role in breaking up a wide partition, preventing high-throughput counter events from overwhelming a given partition. For more information regarding this, refer to this blog.
2. Background Aggregation (Rollups)
Reading individual events for each request is expensive. To solve this, Netflix performs continuous aggregation of events in the background.
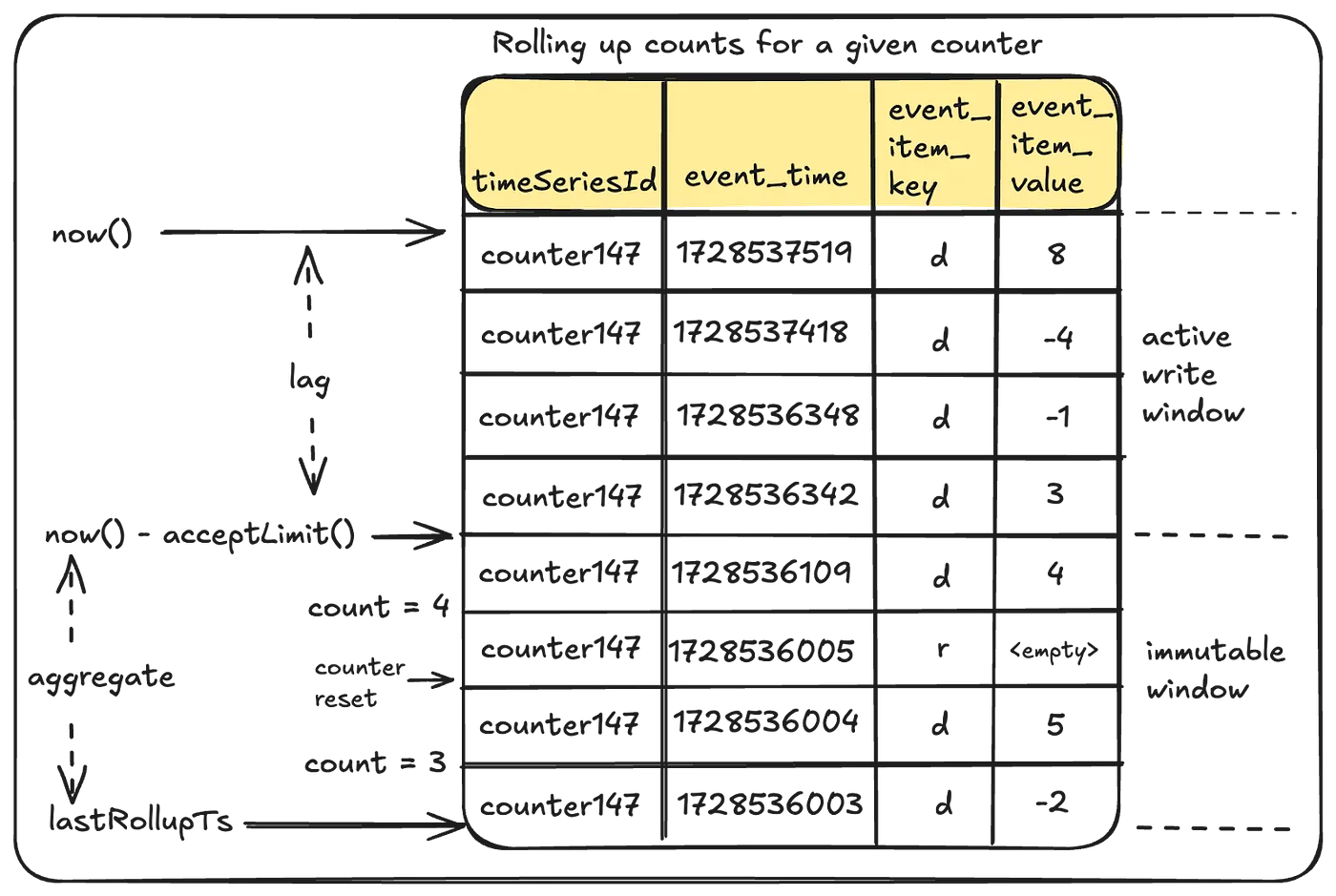
Key points:
Rollup windows: Aggregation occurs within a defined time window to ensure consistency
lastRollupTs: This represents the most recent time when the counter value was last aggregated. For a counter being operated for the first time, this timestamp defaults to a reasonable time in the past.
Immutable window: Aggregation can only occur safely within an immutable window that is no longer receiving counter events. The “acceptLimit” parameter of the TimeSeries Abstraction plays a crucial role here, as it rejects incoming events with timestamps beyond this limit. During aggregations, this window is pushed slightly further back to account for clock skews.
This results in a rollup count, which represents the sum of all events in the aggregation window.
3. Rollup Storage
Aggregated counts are stored in a persistent Rollup store, again often Cassandra, with one table per dataset.
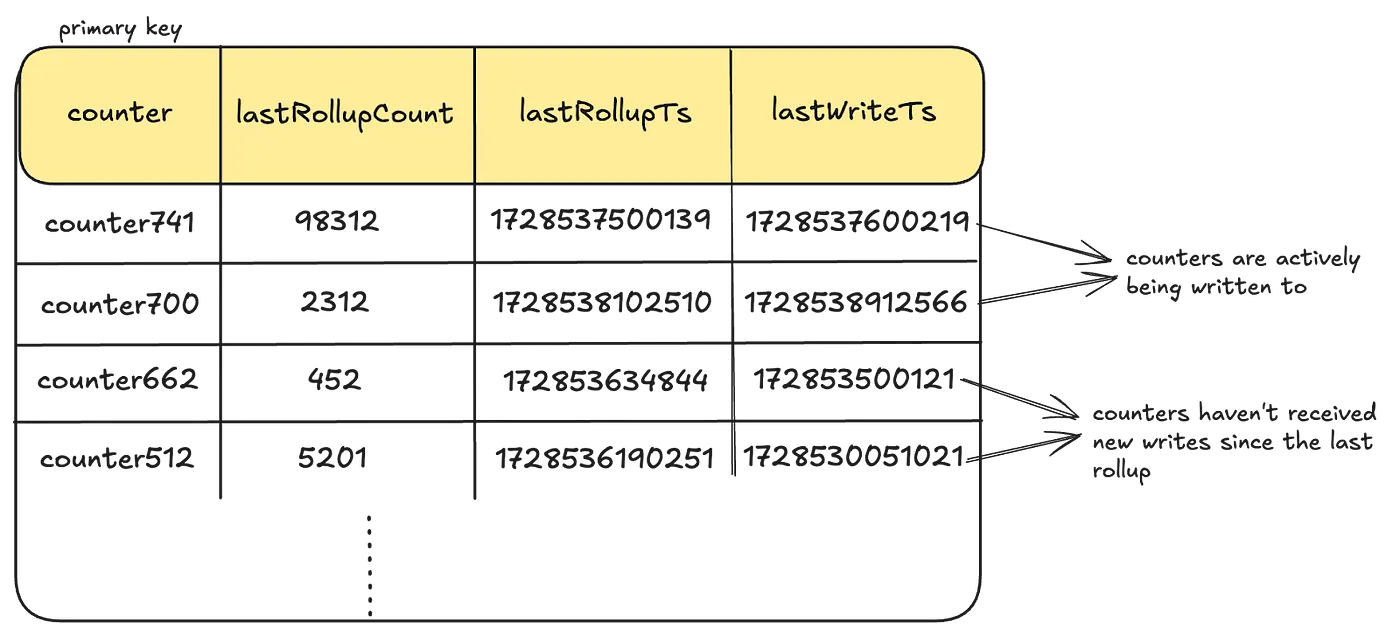
LastWriteTs: Every time a given counter receives a write, they also log a last-write-timestamp as a columnar update in this table. This is done using Cassandra’s USING TIMESTAMP feature to predictably apply the Last-Write-Win (LWW) semantics. This timestamp is the same as the event_time for the event.
Each row contains:
counter_name,lastRollupCount,lastRollupTsLastWriteTsis recorded for every write to track whether the counter has new events not yet aggregated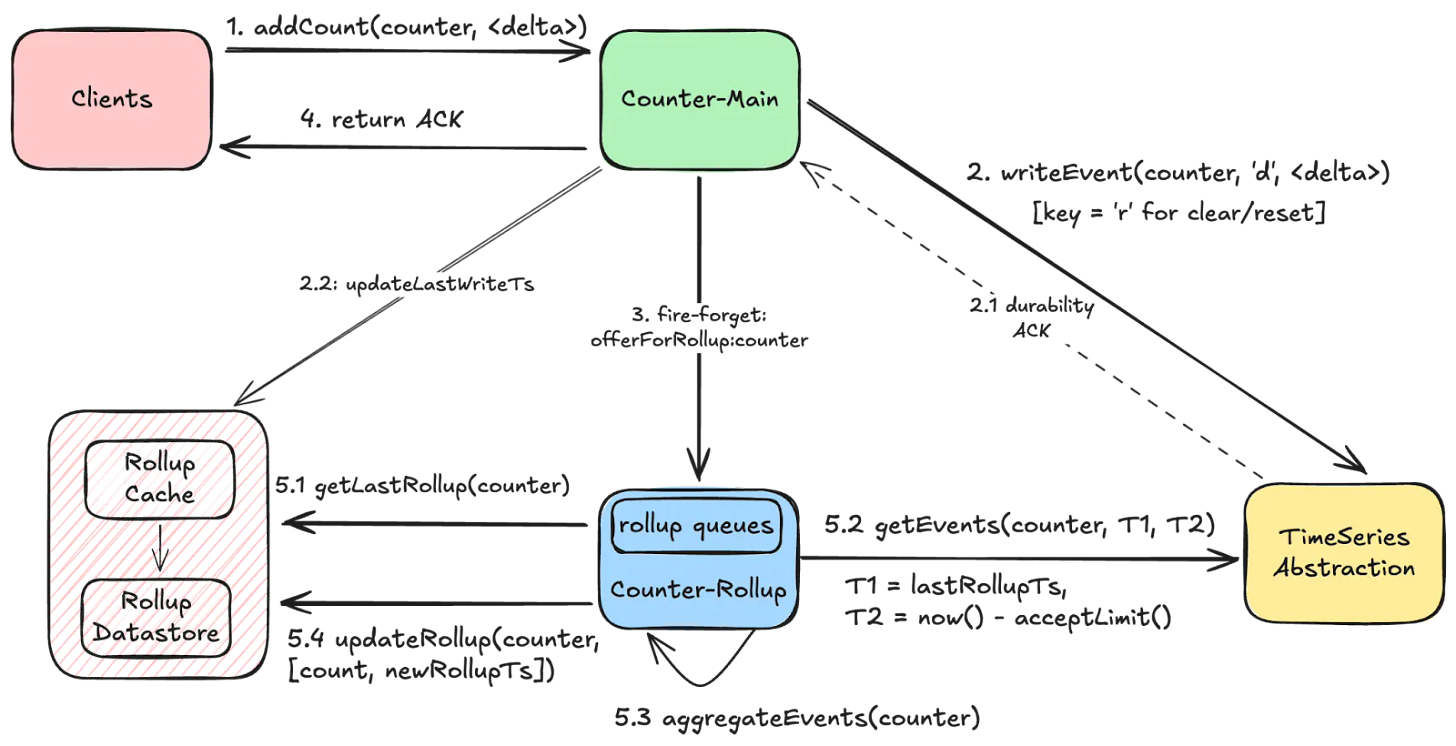
Subsequent aggregations continue from the last checkpoint
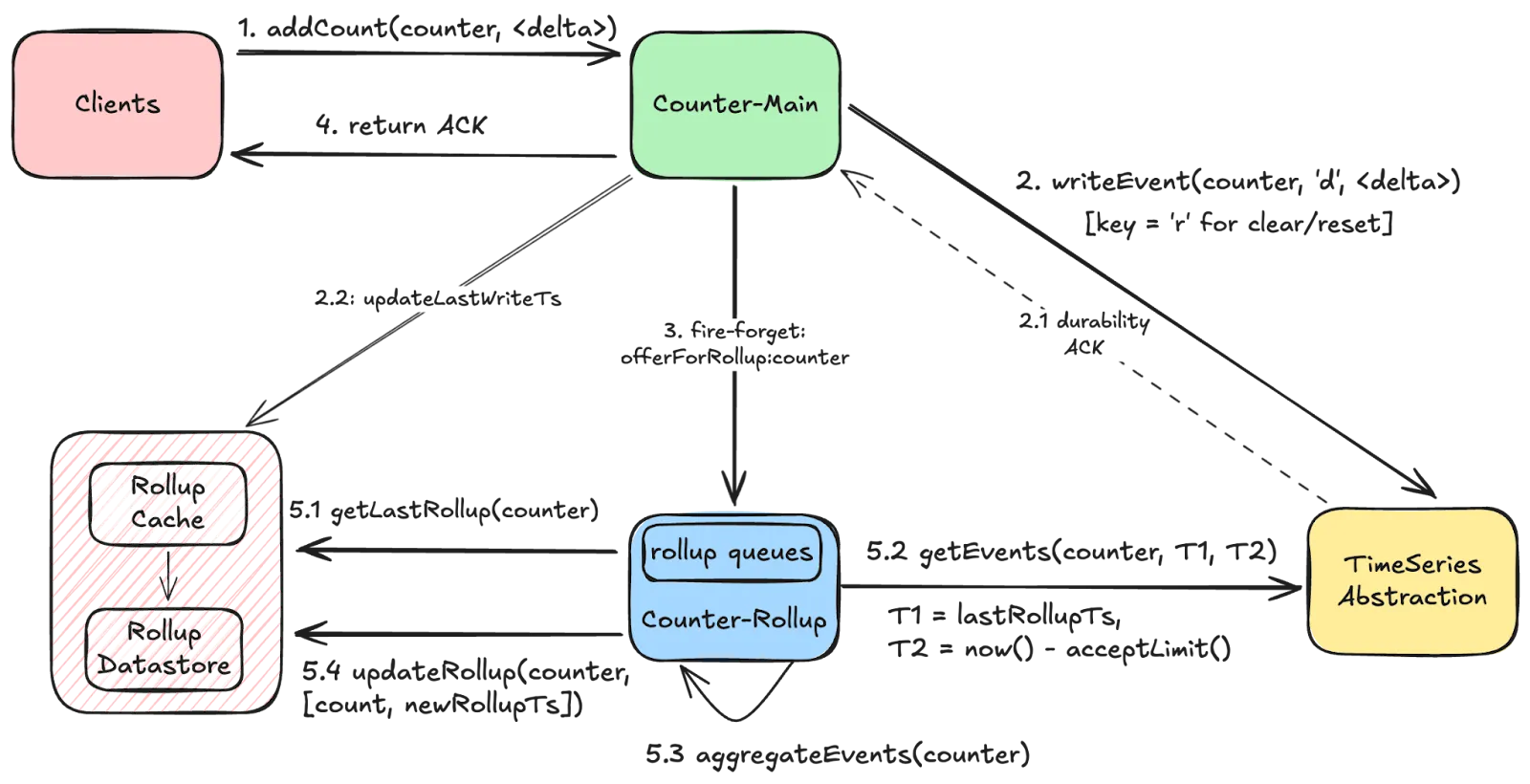
Benefit: Efficient reads with only incremental aggregation needed
4. Caching Layer (EVCache)
To provide low-latency reads, the latest aggregated counts are cached in EVCache.
Cached value =
{lastRollupCount, lastRollupTs}
Reads return the cached value, with a slight acceptable lag
Triggers a rollup in the background if needed to catch up on events

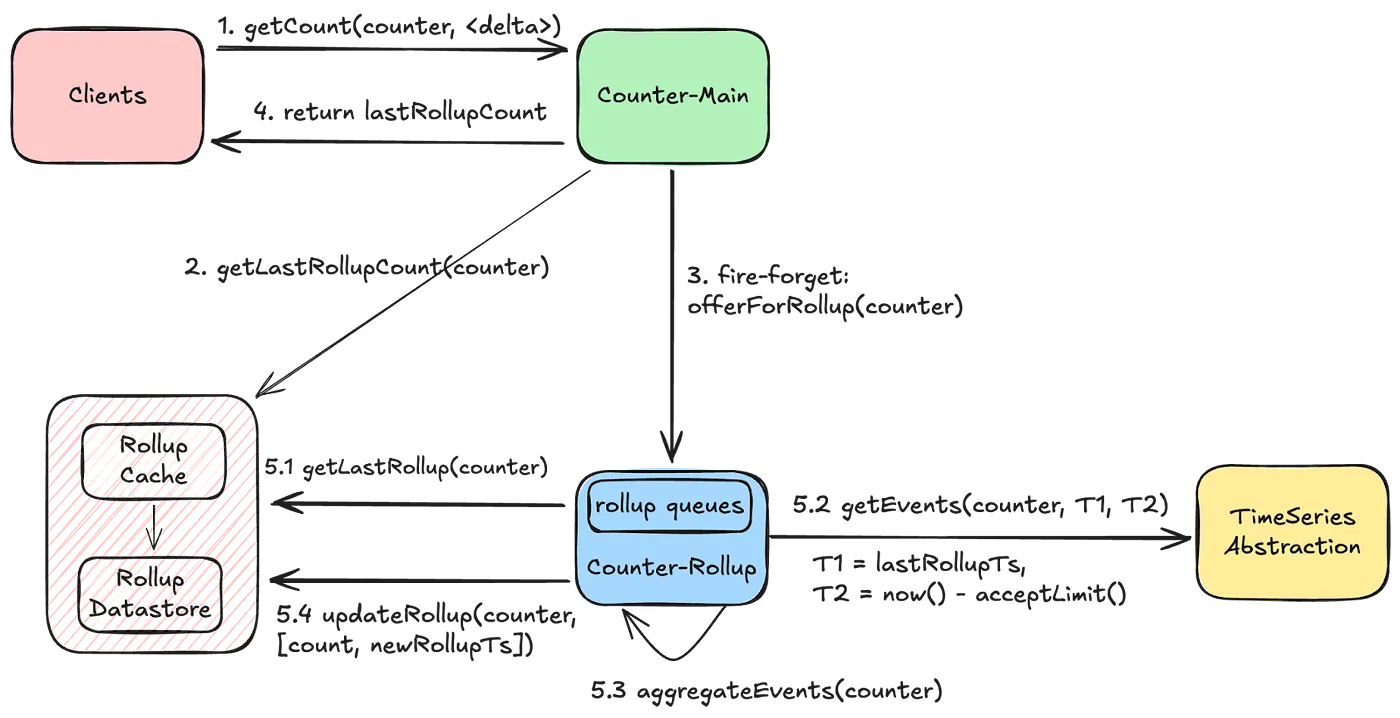
This allows single-digit millisecond read latencies even at massive scale.
5. Event-Driven Rollup Pipeline
Rollups are triggered using a lightweight rollup event per counter.
rollupEvent: {
“namespace”: “my_dataset”,
“counter”: “counter123”
}This event doesn’t contain the actual number that was added to the counter. Instead, it just tells the Rollup server that this counter was updated and needs to be processed. By sending these lightweight “update signals,” the system knows exactly which counters to aggregate, so it doesn’t have to go through all the events in the database every time.
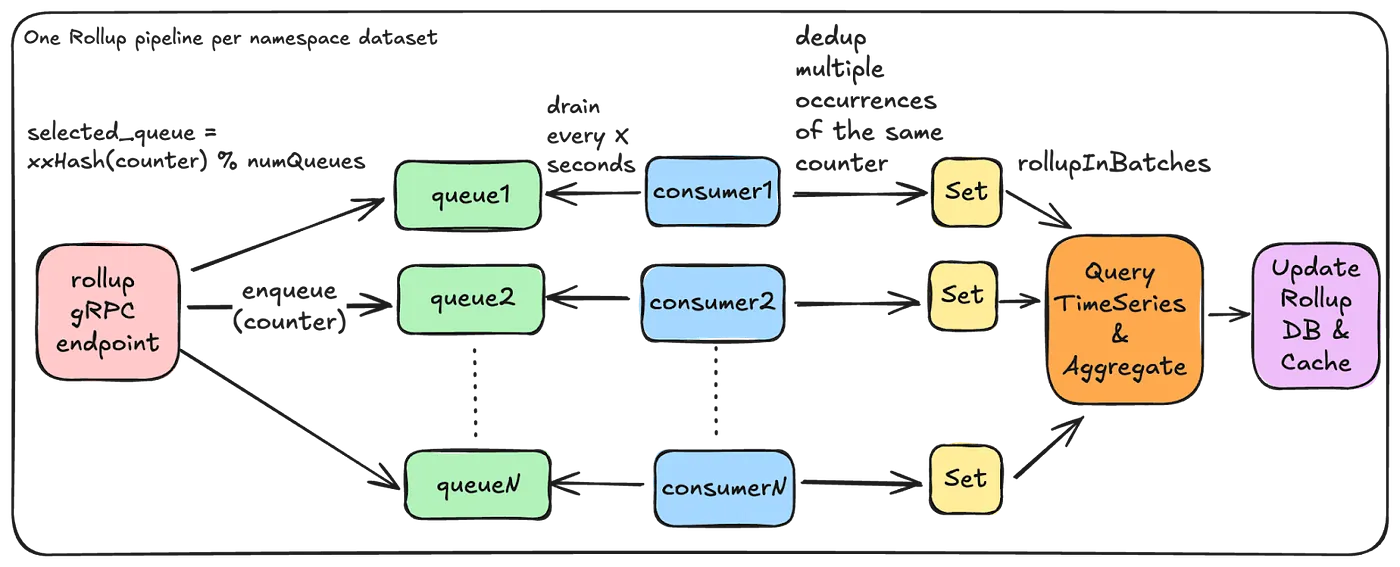
In-Memory Rollup Queues: Each Rollup server keeps several queues in memory to collect rollup events and process multiple counters at the same time. Using in-memory queues makes the system simpler, cheaper, and easier to adjust if they need more or fewer queues. The trade-off is that if a server crashes, some rollup events in memory might be lost.
Minimize Duplicate Effort: Netflix uses a fast non-cryptographic hash like XXHash to ensure that the same set of counters end up on the same queue. Further, Netflix tries to minimize the amount of duplicate aggregation work by having a separate rollup stack that chooses to run fewer beefier instances.
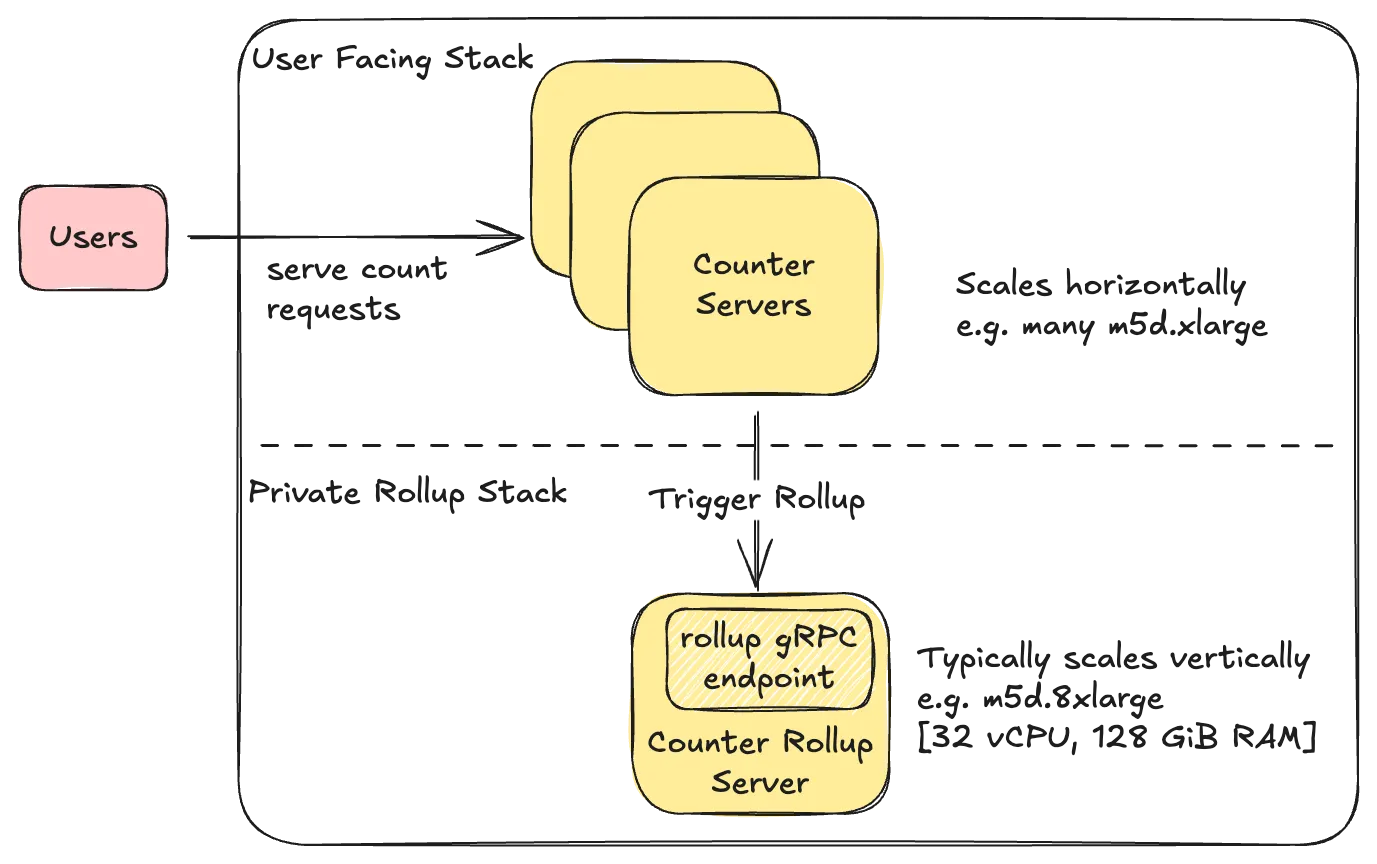
Dynamic Batching: The Rollup server dynamically adjusts the number of time partitions that need to be scanned based on cardinality of counters in order to prevent overwhelming the underlying store with many parallel read requests.
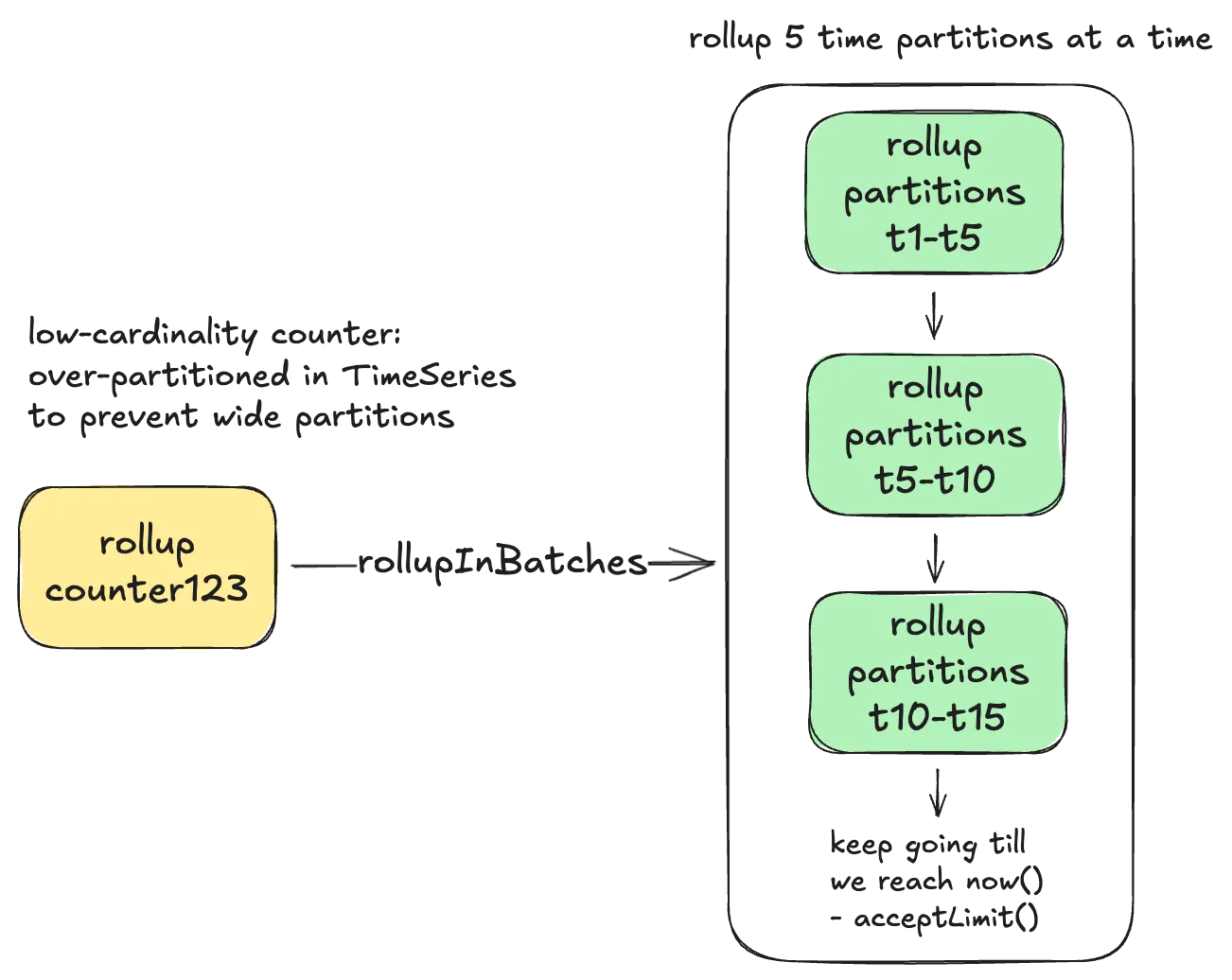
Adaptive Back-Pressure: Each consumer waits for one batch of counters to finish processing before starting the next batch. If the previous batch took longer, the system waits a bit more before starting the next one. This helps prevent the underlying TimeSeries database from getting overloaded with too many requests at once.
Key Considerations:
Aggregation occurs without distributed locks, using immutable windows to ensure correctness
Counters are re-queued if new writes occur, ensuring convergence
Stale counts self-remediate during the next read-triggered rollup
6. Idempotency and Safety
Each increment event includes event_id + event_time as a unique key. This ensures:
Safe retries without over-counting
Accurate aggregation across distributed consumers
Reliable reset operations without race conditions
7. Experimental “Accurate” Counter
For use cases requiring near real-time accurate counts:
The delta between the last rollup and current events is computed in real-time during read
currentAccurateCount = lastRollupCount + deltaBatched processing is still applied to avoid overwhelming the underlying TimeSeries store
This allows clients to see almost real-time counts, while the system maintains high throughput for millions of counters globally.
Putting It All Together
The final architecture combines:
Event logging: Every increment is stored as an immutable event in TimeSeries
Background aggregation: Continuous rollups ensure efficient reads
Rollup storage: Persistent storage for aggregated counts
Caching: EVCache for near-instant reads
Event-driven pipeline: Efficient, parallel, and idempotent rollups
Optional real-time delta: For “accurate” counter reads
This combination of event logging, aggregation, caching, and idempotency is what allows Netflix to:
Handle millions of simultaneous increments
Provide near real-time counts
Avoid overloading any single server
Maintain global durability and reliability
Key Design Takeaways
Netflix’s distributed counting system is a perfect example of how simple ideas need solid architecture at scale.
Push computation closer to data
Let each node do part of the work instead of relying on one big systemBatch operations
Do not send every single event. Aggregate small chunks to reduce loadDesign for eventual consistency
It is okay if data takes a few seconds to settle as long as it converges correctlyUse idempotent events
Avoid double-counting when messages are retriedStream, don’t store
Use event-driven architecture for scalability and resilience
Reference: Netflix’s Distributed Counter Abstraction
Final Thoughts
I love how Netflix engineers turn “simple problems” into lessons in elegant system design.
Distributed counting teaches us that even a basic count++ can become complex when scaled across thousands of machines. With the right architecture, batching, and event streaming, it becomes not just manageable but efficient.
It is a reminder that great engineering is about scaling simplicity, not complexity.
Next time you design a system, ask yourself:
What happens when this “simple” feature needs to scale to a billion users?
That is where system design truly begins.
Checkout more on my website https://rahuldhar.me