

My Journey Understanding an Inherited PostgreSQL System
Why Your Database Ignores Indexes: A Journey Through Planner Mysteries and Design Choices

The Puzzle That Started It All
In a recent project I worked on, I was puzzled by what seemed like an inconsistent indexing situation. This inconsistency bothered me, so I decided to dig deeper. What I discovered taught me that "wrong" isn’t always wrong. It is often about trade-offs I hadn’t considered.
The Starting Point: A Confusing Primary Key
The first thing that caught my attention was the primary key design:
CREATE TABLE locations (
location_id TEXT NOT NULL, -- e.g., 'A01020304' (hierarchical location code)
warehouse_id TEXT NOT NULL, -- e.g., '25'
-- ... other columns
CONSTRAINT pk_locations_location_id_warehouse_id
PRIMARY KEY (location_id, warehouse_id)
);
This struck me as backwards. In most multi-tenant systems I've worked with, you'd cluster by warehouse_id first for tenant isolation. But here, location_id comes first. I wondered if this was a mistake or if there was reasoning I wasn't seeing.
Understanding the Location ID Structure
As I dug deeper, I discovered that these location IDs weren't just random strings. They followed a specific hierarchical structure that was key to understanding the whole system. Each warehouse had thousands (sometimes millions) of storage locations, and every location was encoded into a structured string ID.
For example, a location ID like A01020304 breaks down as:
Aisle:
A01(an uppercase letter + 2 digits)Bay:
02(2 digits)Level:
03(2 digits)Position:
04(2 digits)
When someone searches for A01%, they're looking for all locations in aisle A01 across any warehouse. When they search for H1%, they want all locations in aisles starting with H1. This spatial organization is crucial for warehouse operations. workers need to find adjacent locations, analyze storage density by aisle, or audit entire sections of the warehouse.
My First Breakthrough: The Migration History
Curious about the primary key design, I dug through the database migration history. What I found surprised me:
Original Design (October 2023)
PRIMARY KEY (warehouse_id, location_id) -- Warehouse firstChanged to (February 2025)
PRIMARY KEY (location_id, warehouse_id) -- Location firstSo it wasn't a mistake! The previous team had deliberately switched the primary key ordering. This made me even more curious. What drove that decision? And more importantly, I started noticing something concerning in my testing: PostgreSQL kept avoiding this index, even when it seemed like it would be faster.
My Testing Adventure: When the Planner Surprised Me
This is where my investigation got really interesting. I decided to systematically test different query patterns to understand when PostgreSQL was making good choices versus poor ones. What I found challenged everything I thought I knew about query optimization.
Test 1: Location Pattern Query
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT location_id, warehouse_id
FROM locations
WHERE location_id LIKE 'H1%';
Result: 477ms with parallel sequential scan for 92,689 rows (~4% of table)
PostgreSQL chose sequential scan, which makes sense for large result sets.
Test 2: Warehouse-Specific Query
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT location_id, warehouse_id
FROM locations
WHERE warehouse_id = '25';
Natural planner choice: 567ms (sequential scan) Forced index usage: 282ms (50% faster!)
SET enable_seqscan = false;
-- Same query runs in 282ms with bitmap index scan
RESET enable_seqscan;
Test 3: Combined Query
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT location_id, warehouse_id
FROM locations
WHERE warehouse_id = '25' AND location_id LIKE 'H1000%';
Natural planner choice: 501ms (sequential scan) Forced index usage: 354ms (29% faster)
Test 4: LIMIT with OFFSET Queries
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT location_id, warehouse_id
FROM locations
WHERE location_id LIKE 'H1%' AND warehouse_id = '09'
LIMIT 100 OFFSET 100;
Natural planner choice: 436ms (sequential scan) Forced index usage: 204ms (53% faster)
-- Natural planner result (sequential scan)
Limit (cost=6560.89..12121.78 rows=100 width=12) (actual time=412.845..436.060 rows=0 loops=1)
-> Gather
-> Parallel Seq Scan on locations
Filter: (((location_id)::text ~~ 'H1%'::text) AND ((warehouse_id)::text = '09'::text))
Rows Removed by Filter: 746758
-- Forced index result
Limit (cost=9743.66..19486.90 rows=100 width=12) (actual time=204.298..204.300 rows=0 loops=1)
-> Index Only Scan using pk_locations_location_id_warehouse_id on locations
Index Cond: (warehouse_id = '09'::text)
Filter: ((location_id)::text ~~ 'H1%'::text)
Rows Removed by Filter: 30265
Key insight: Even with LIMIT + OFFSET, the index scan won significantly. The index could filter by warehouse_id first (30k rows examined) vs. sequential scan examining 746k rows across workers.
Test 5: Simple LIMIT Queries (When the Planner Gets It Right)
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT location_id, warehouse_id
FROM locations
WHERE location_id LIKE 'H1%'
LIMIT 100;
Natural planner choice: 0.579ms (sequential scan) Forced index usage: 321ms (550x slower!)
-- Sequential scan result
Limit (cost=0.00..91.49 rows=100 width=12) (actual time=0.035..0.553 rows=100 loops=1)
-> Seq Scan on locations
Filter: ((location_id)::text ~~ 'H1%'::text)
Rows Removed by Filter: 3060
-- Forced index scan result
Limit (cost=0.43..224.78 rows=100 width=12) (actual time=321.386..321.501 rows=100 loops=1)
-> Index Only Scan using pk_locations_location_id_warehouse_id on locations
Filter: ((location_id)::text ~~ 'H1%'::text)
Rows Removed by Filter: 433527
Here, the planner was absolutely correct! Sequential scan found 100 results after examining only 3,160 rows, while the index scan had to examine 433,627 rows to find the same 100 results.
Why LIMIT changes everything:
Sequential scan can stop as soon as it finds enough rows
H1% patterns are distributed throughout the data
Index scan must traverse scattered index pages to find matches
For small result sets, "first 100 found" beats "optimally ordered access"
Summary: When Indexes Help vs. Hurt
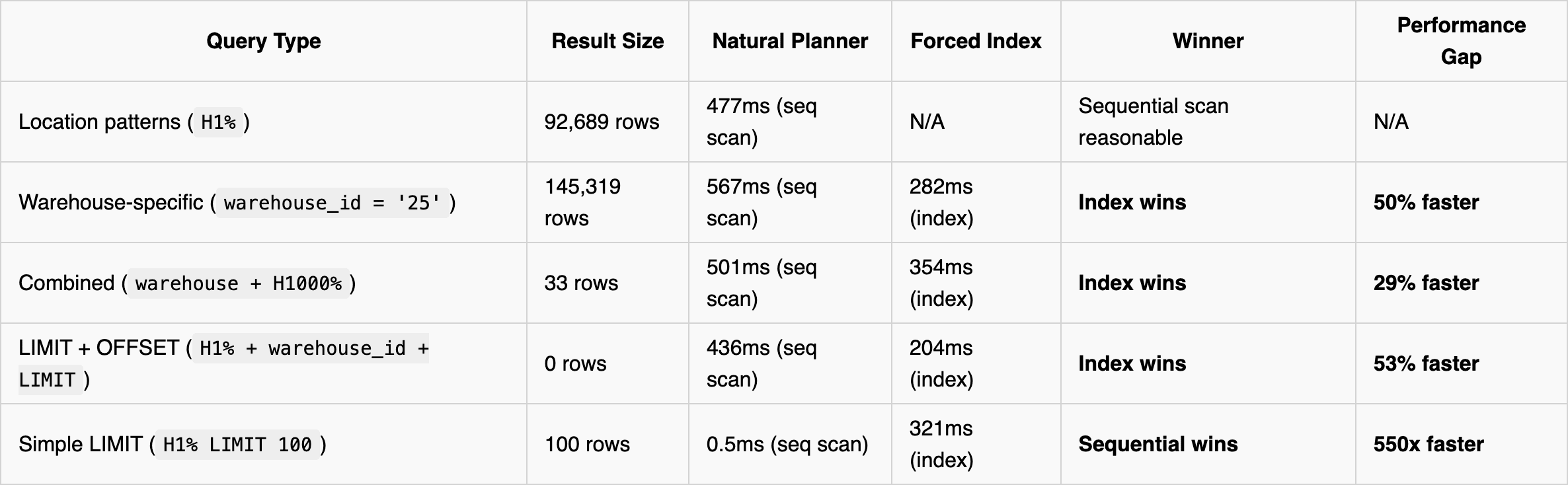
The Pattern:
Large scans: Sequential wins or is reasonable
Medium selectivity with filtering: Index wins significantly (even with LIMIT + OFFSET)
Simple LIMIT queries: Sequential wins dramatically (can stop early)
Understanding Why PostgreSQL Made These Choices
The more I tested, the more I realized there was a pattern to the planner's behavior. PostgreSQL's cost-based optimizer sometimes chose suboptimal plans, but sometimes it was exactly right. I needed to understand the logic behind these decisions.
1. The Cost Model Mystery
I discovered that PostgreSQL uses abstract "cost units" to compare execution strategies. Looking at my system's configuration, I found these parameters:
-- My system's cost parameters (defaults)
SHOW random_page_cost; -- 4.0 (random reads cost 4x sequential!)
SHOW effective_cache_size; -- 1502984kB (~1.5GB in my case)
seq_page_cost = 1.0 -- Cost to read a page sequentially
cpu_tuple_cost = 0.01 -- Cost to process one row
For my warehouse query (warehouse_id = '25' with 6.5% selectivity), the planner calculated:
Sequential scan cost: ~67,000 units (read entire table sequentially, low per-page cost)
Index scan cost: ~130,000 units (random index + heap access, 4x page cost penalty)
This explained why PostgreSQL kept choosing sequential scans! The planner assumed random I/O was 4x more expensive than sequential I/O. But when I forced the index usage, it was actually 50% faster. The cost model seemed to be wrong about modern storage characteristics.
2. The Index Scattering Problem
I realized that with the (location_id, warehouse_id) primary key structure I inherited:
All warehouse '25' locations were scattered throughout the index
To find them, the index scan had to jump between many different location_id ranges (A01..., B01..., H1...)
This created the "random" access pattern that the cost model was heavily penalizing
3. Statistics vs. Reality
Interestingly, PostgreSQL's row count estimates were quite accurate (144k estimated vs 145k actual rows). The problem wasn't with statistics - it was with cost estimation. The planner didn't account for:
How efficiently modern SSDs handle the "random" access patterns
How much of the data was already cached in the 1.5GB buffer pool
How well bitmap heap scans actually perform on this hardware
My Analysis: Was This Bad Design?
The big question that kept bugging me: When the planner consistently chooses slower execution plans, does that mean the database design is wrong?
My Conclusion: It's All About Trade-offs
As I analyzed the system deeper, I realized the primary key design created a fundamental trade-off:
Location-first ordering
(location_id, warehouse_id)optimized for:Global operations spanning all warehouses.
Spatial analysis across the entire location hierarchy
But it penalized warehouse-specific queries because:
Warehouse data became scattered throughout the index
This forced "random" access patterns that the cost model heavily penalized
Understanding the Previous Team's Logic
Looking back at the migration history, I realized this was a completely deliberate decision:
October 2023: PRIMARY KEY (warehouse_id, location_id) (conventional multi-tenant design)
February 2025: PRIMARY KEY (location_id, warehouse_id) (location-first optimization)
The team had switched from the "obvious" warehouse-first design to location-first. This told me:
Cross-warehouse location queries were more critical to the business than warehouse isolation
They had probably measured the performance impact and decided the trade-off was worth it
The 50% penalty for warehouse queries was acceptable given their workload priorities
Issue with the query planner: Outdated cost assumptions
The more I studied this, the more I realized the problem wasn't the index design - it was PostgreSQL's cost model being outdated for modern hardware:
The cost model assumed random I/O was 4x more expensive than sequential
Modern SSDs and the 1.5GB buffer pool made this assumption much less relevant
Bitmap heap scans performed better than the planner estimated on this hardware
What I Learned and How I'd Optimize This System
1. Query Planner "Mistakes" Are Often Normal
My investigation taught me that query planners making suboptimal choices is more common than I expected, especially:
On modern hardware (SSDs, large RAM)
With index designs that optimize for specific business patterns
When cost models haven't kept up with hardware evolution
2. The Power of Testing Assumptions
I developed a methodical approach to test when the planner might be wrong, but learned to be careful with LIMIT queries:
-- My testing approach for the warehouse queries
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM locations WHERE warehouse_id = '25';
-- Force index usage to compare
SET enable_seqscan = false;
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM locations WHERE warehouse_id = '25';
RESET enable_seqscan;
-- But I learned LIMIT queries often favor sequential scans
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM locations WHERE location_id LIKE 'H1%' LIMIT 100;3. How I'd Optimize: Supplemental Indexes
Based on my analysis, if I were optimizing this system, I'd add a supporting index to get the best of both worlds:
-- Add this to optimize warehouse-specific queries
CREATE INDEX CONCURRENTLY idx_locations_warehouse_location
ON locations (warehouse_id, location_id);
This would preserve the benefits of the location-first primary key while eliminating the 50% performance penalty for warehouse queries.
4. Cost Model Tuning Experiments I'd Try
I realized this system would benefit from tuning PostgreSQL's cost model to reflect modern hardware realities:
-- Current settings that explain the planner behavior
SHOW random_page_cost; -- 4.0 (assumes spinning disks!)
SHOW effective_cache_size; -- 1502984kB (~1.5GB in our case)
-- Experiments I'd try:
SET random_page_cost = 1.1; -- Reflect SSD performance characteristics
SET effective_cache_size = '4GB'; -- If more memory is available
Lowering random_page_cost would make index scans more attractive to the planner, since it would reduce the penalty for the "random" I/O operations that modern SSDs handle efficiently.
References supporting these tuning approaches:
PostgreSQL Wiki: Tuning Your PostgreSQL Server - Recommends
random_page_cost = 1.1for SSDsPostgreSQL Documentation: Runtime Configuration - Official guidance on cost parameters
PostgreSQL Performance Tuning Guide - SSD optimization recommendations
My Key Discoveries
Query planners aren't perfect, but they're not always wrong - PostgreSQL made poor choices for most of my tests but excellent choices for simple LIMIT queries
Context matters enormously - Simple LIMIT queries favoured sequential scans (0.5ms vs 321ms), but LIMIT + OFFSET + filtering favoured indexes (204ms vs 436ms)
Index design creates trade-offs - the
(location_id, warehouse_id)design optimized cross-warehouse patterns but penalized warehouse isolationCost models lag hardware - PostgreSQL's assumptions about I/O costs didn't match modern SSD and RAM characteristics in my testing
Testing assumptions is crucial - when queries seemed slow, testing alternative execution strategies with
SET enable_seqscan = falserevealed significant performance gapsLIMIT queries favour sequential scans - when I only needed the first N results, sequential access often won dramatically
My Bottom Line: This inherited system wasn't "wrong" - PostgreSQL's query planner was being conservative based on outdated I/O cost assumptions. The primary key design reflected deliberate business optimization choices, and the performance gaps I observed could be addressed with supplemental indexes if needed.
Testing performed on PostgreSQL 15+ with ~2.24M rows. Results may vary based on hardware, configuration, and data distribution.